| Evaluation approach | Lowland-area weight (%) | Highland-area weight (%) | Overall RMSE |
|---|---|---|---|
| Germany domain (target distribution) | 50 | 50 | 0.667 |
Rethinking
Validation
for Spatial Machine Learning
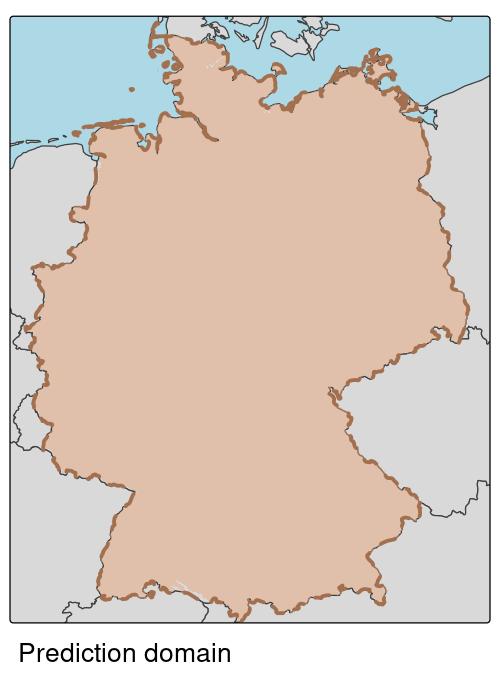
Predictive spatial machine learning
- We are interested in mapping across the spatial domain
- Thus, we should evaluate the map, not the model
- But this raises a key question: What assumptions are we making about spatial evaluation?
Similar application domain
We have this:

We want to predict here:
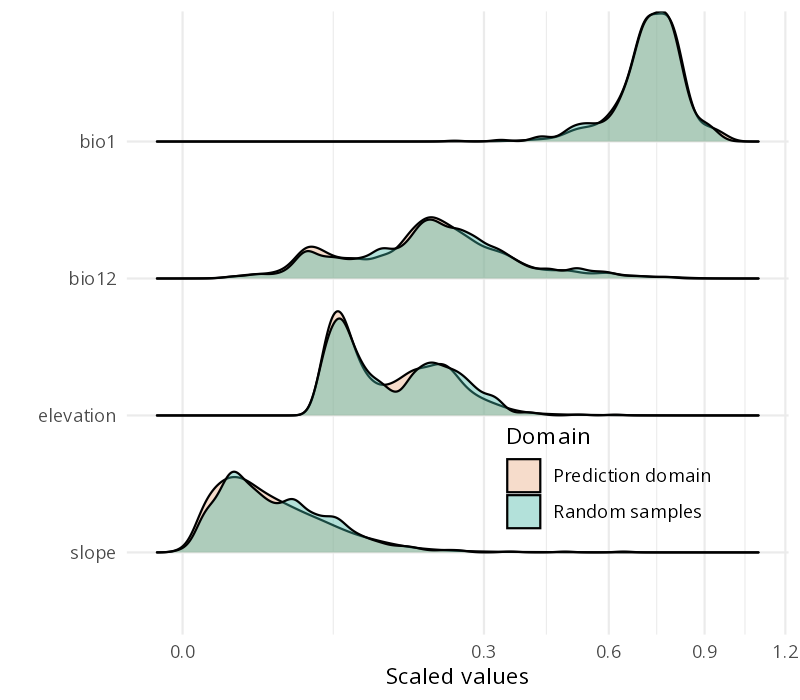
Similar application domain
We have this:
Our predictor distributions are similar here:
Different application domain
We have this:

We want to predict here:
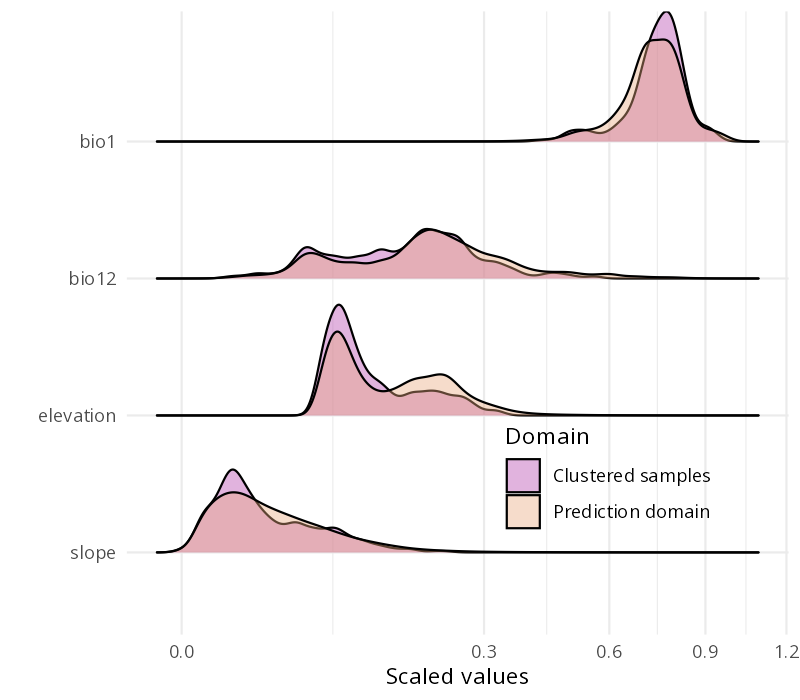
Different application domain
We have this:
Our predictor distributions are a bit different here:
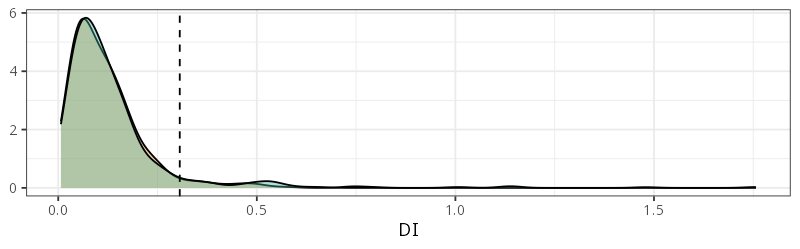
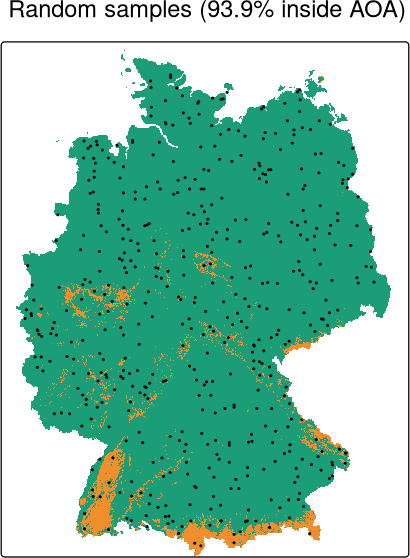
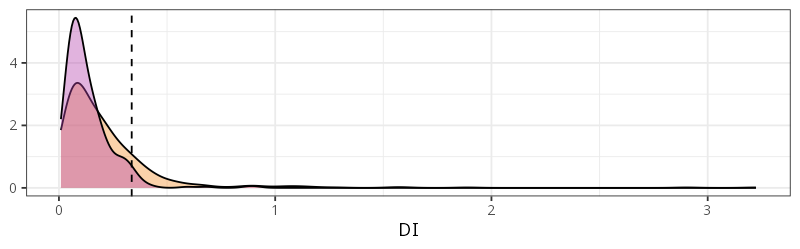
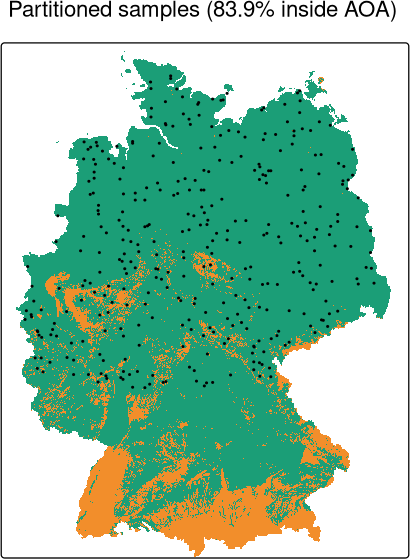
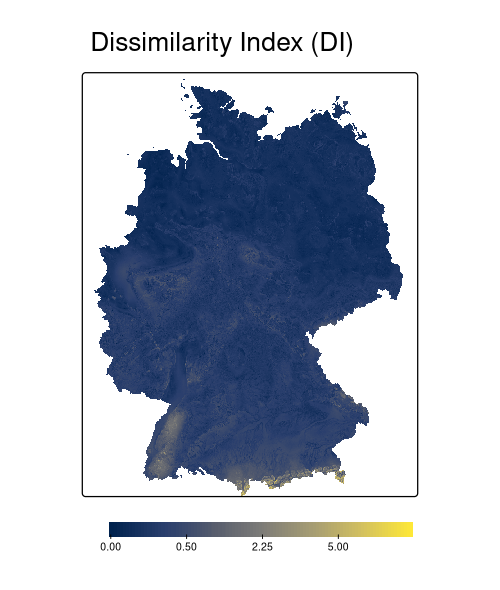
Area of applicability
Identify areas where the environment is not well represented, making predictions less trustworthy (Area of Applicability – AoA, Meyer and Pebesma, 2021); also local point density (LPD, Schumacher et al., 2025)
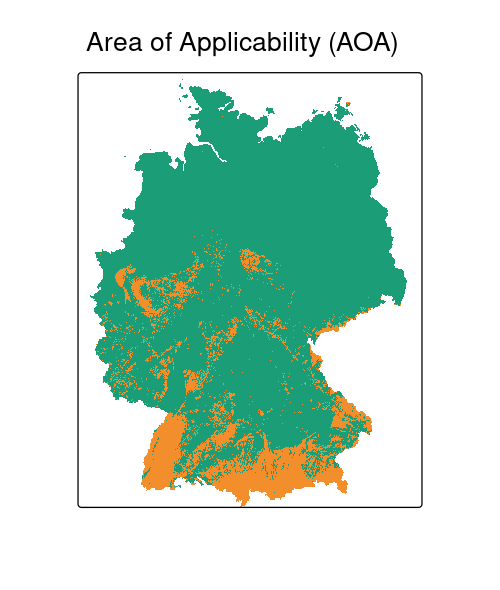
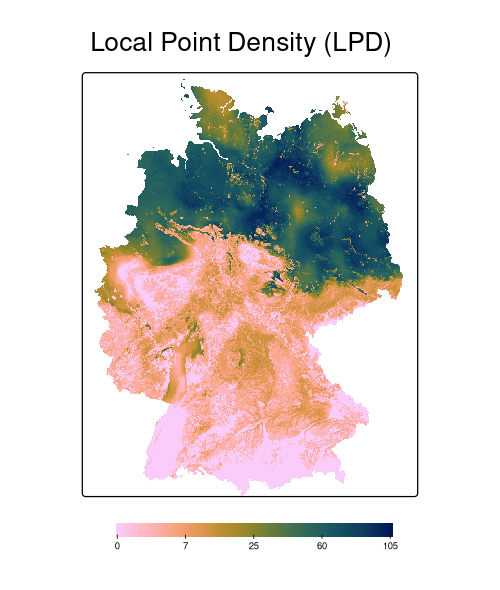
Prediction difficulty depends on prediction domain
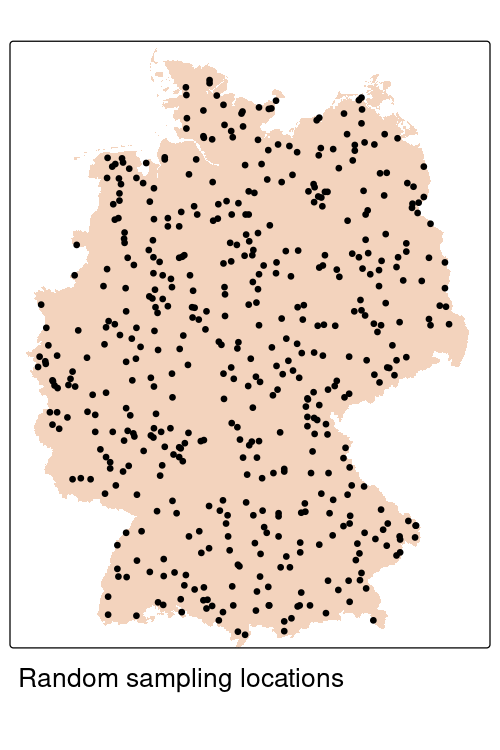
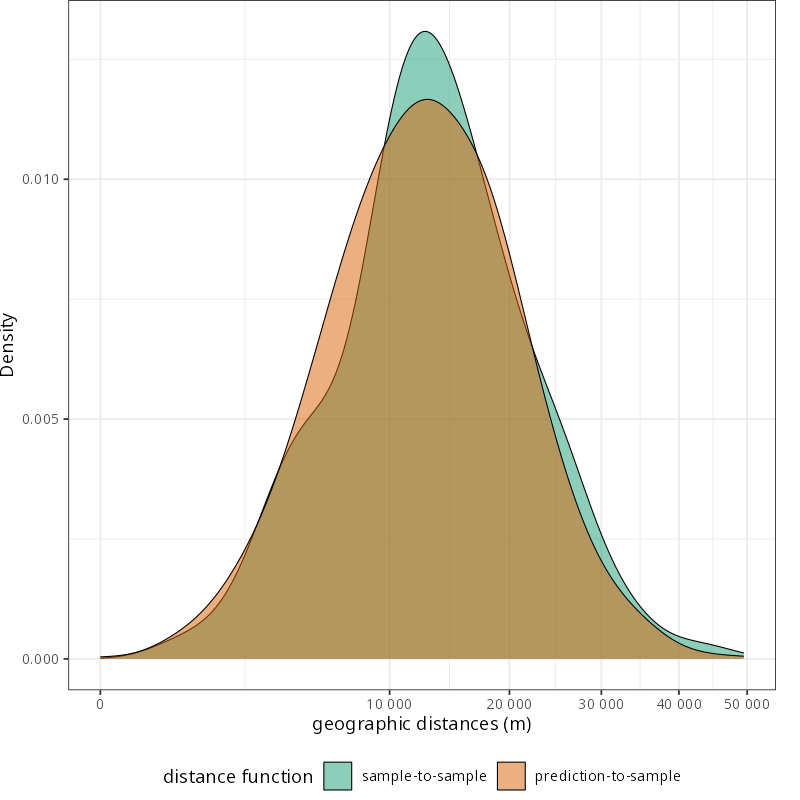
Prediction difficulty depends on prediction domain
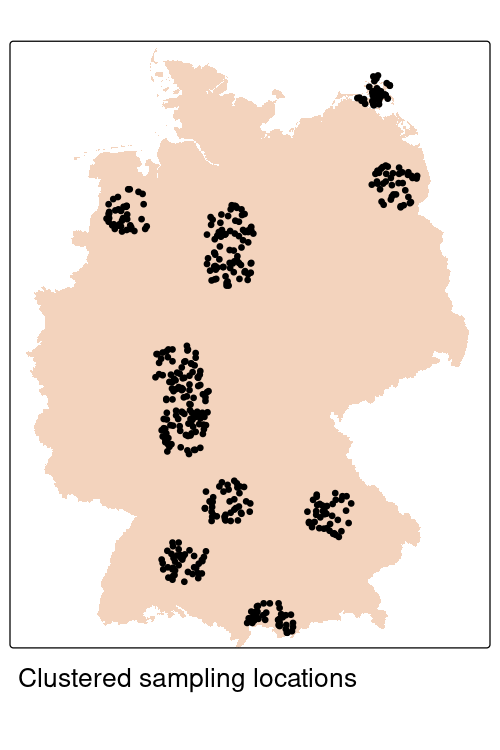
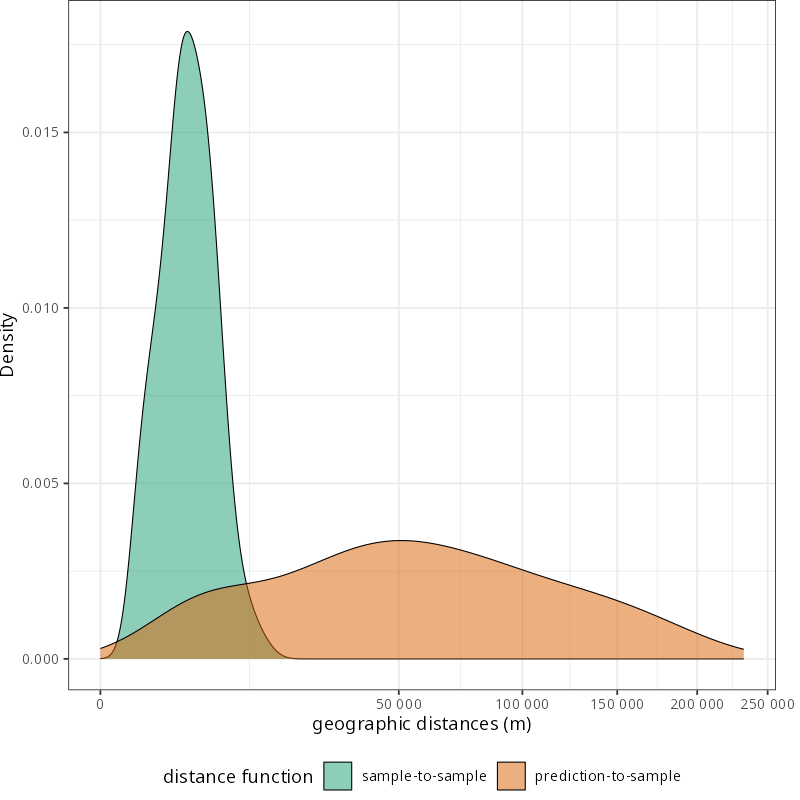
Extrapolation continuum
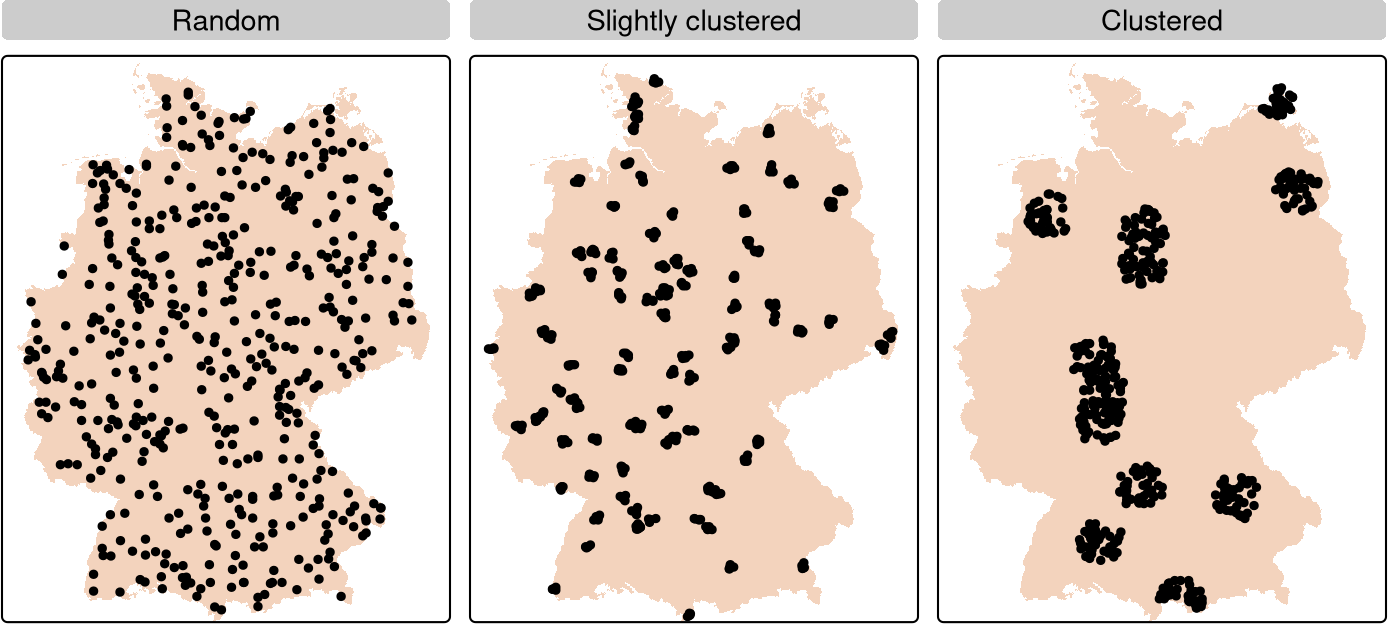
Specific evaluation strategy

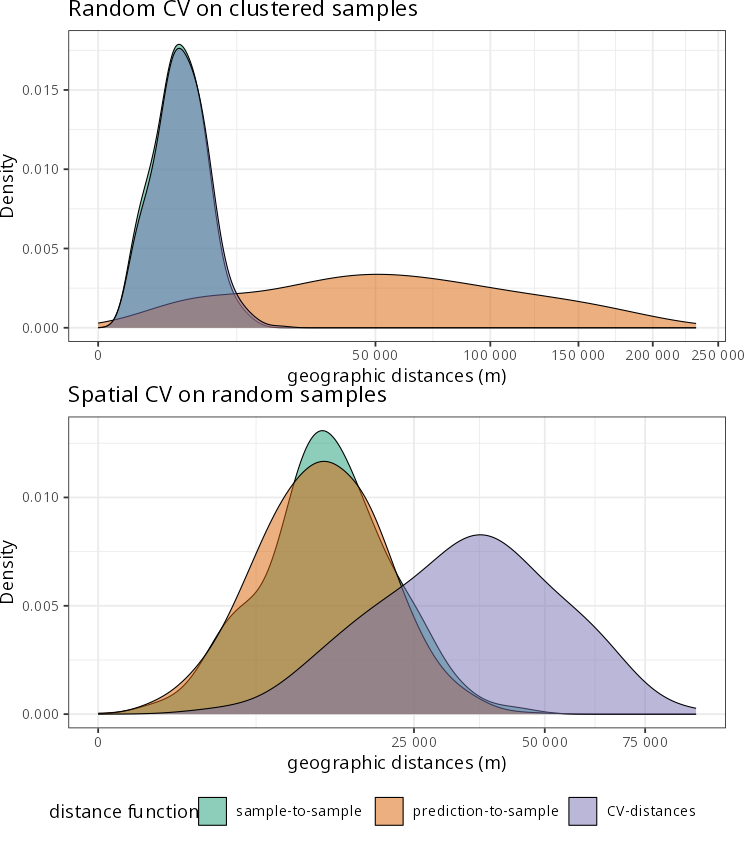
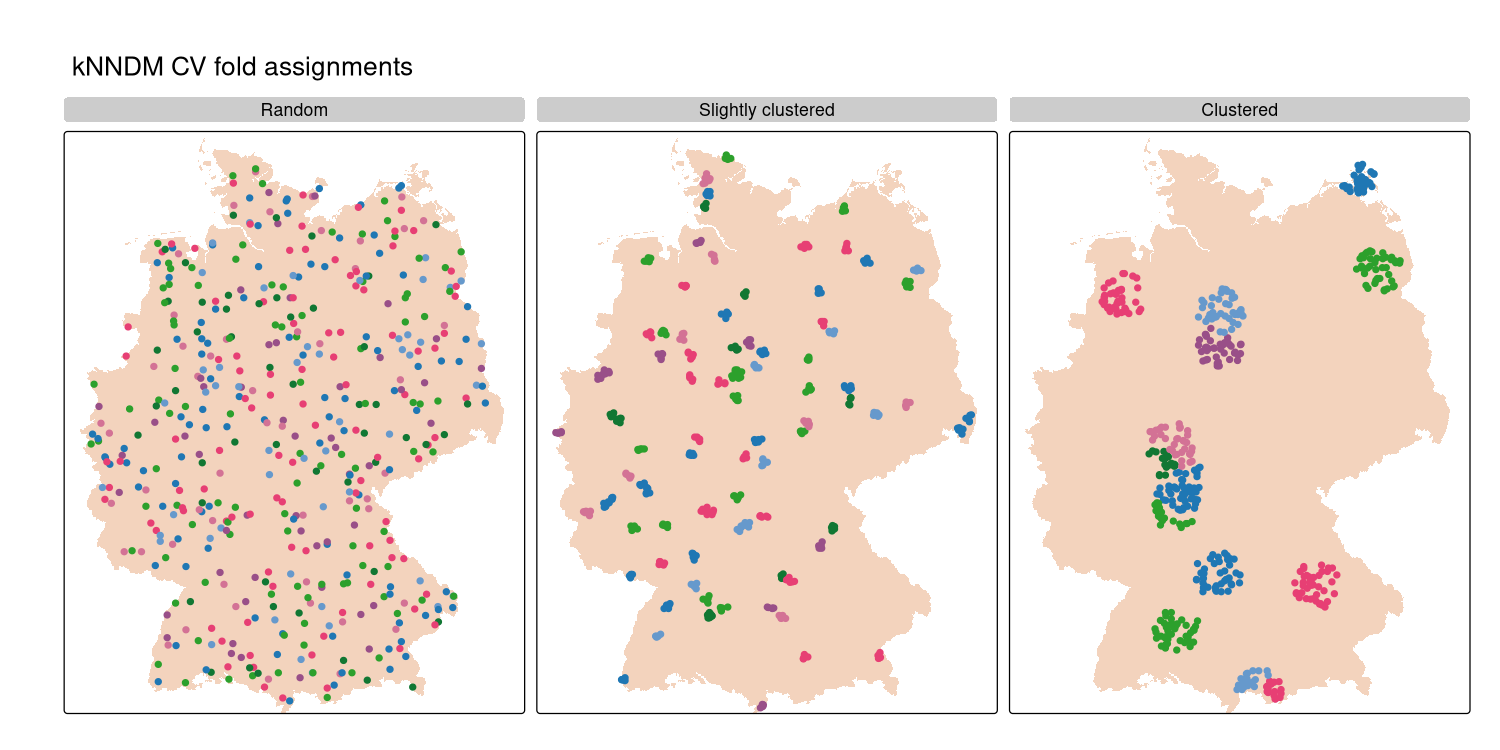
Adaptive evaluation (kNNDM)
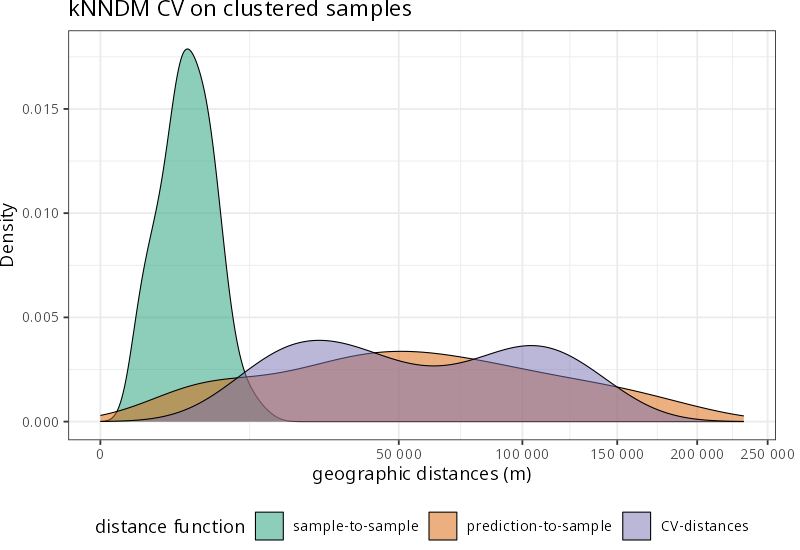
k-Nearest Neighbor Distance Matching (kNNDM, Linnenbrink et al., 2024) matches folds to the prediction scenario using distance structure (either in geographic or predictor space).
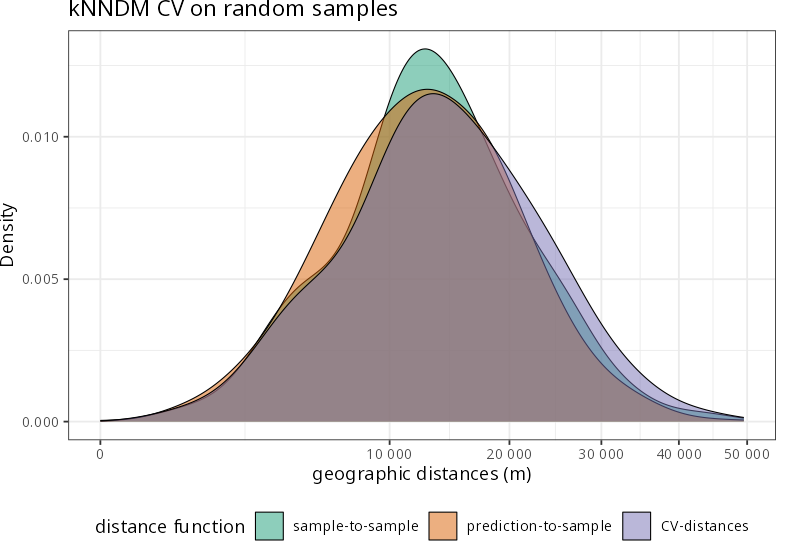
Overlapping predictor distribution(s)
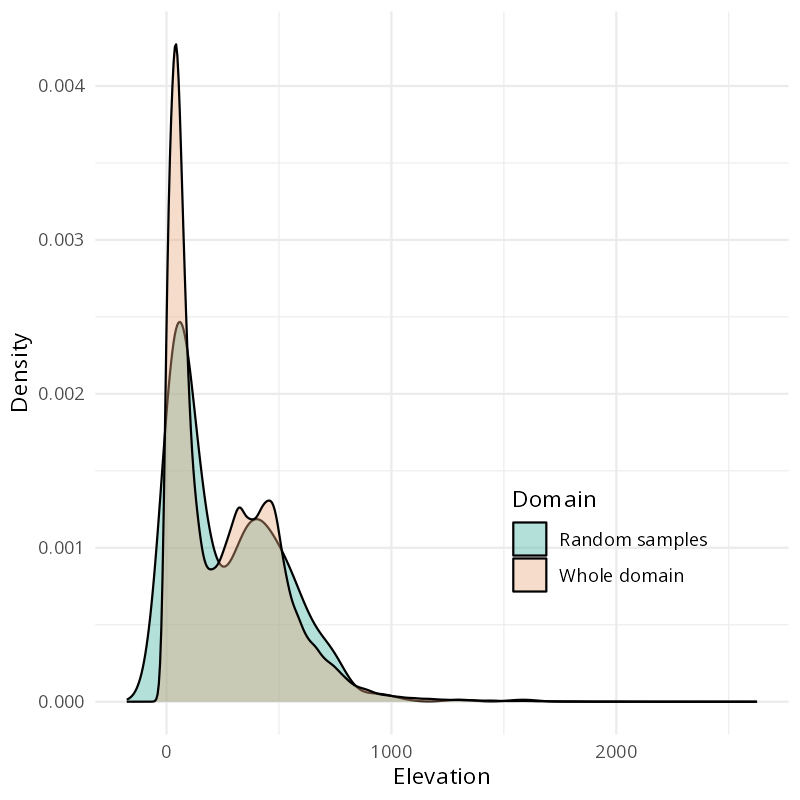
Partially overlapping predictor distribution(s)
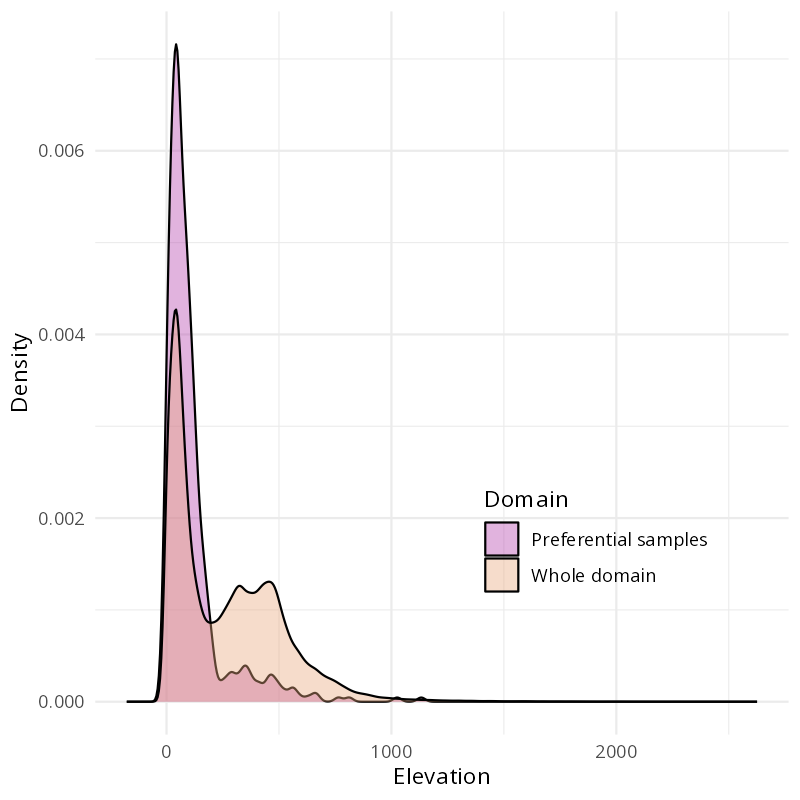
Approaches to reweighting
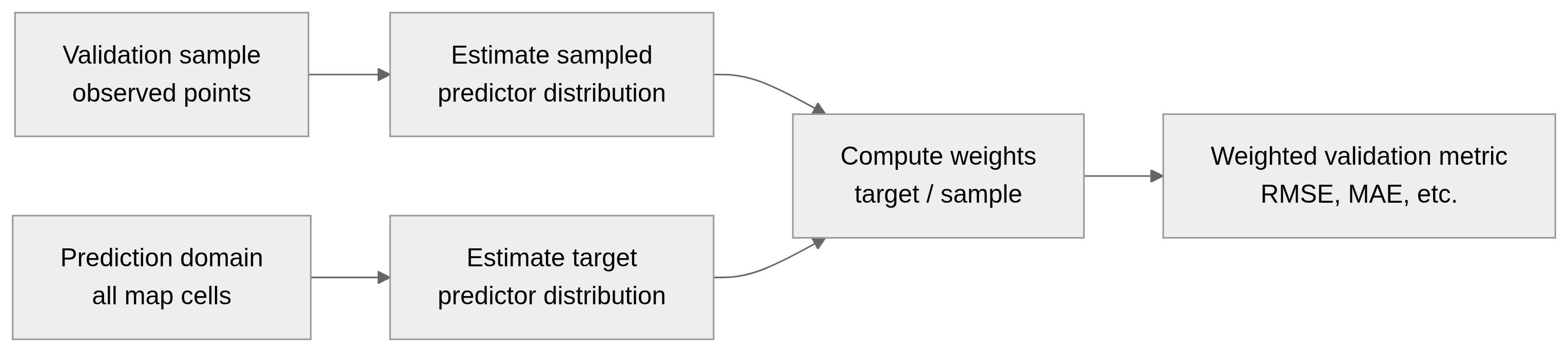
Target-Weighted Cross-Validation (TWCV, Brenning and Suesse, 2026) adjusts cross-validation weights to align evaluation with the prediction domain rather than the sampled data distribution.
A piece of evidence
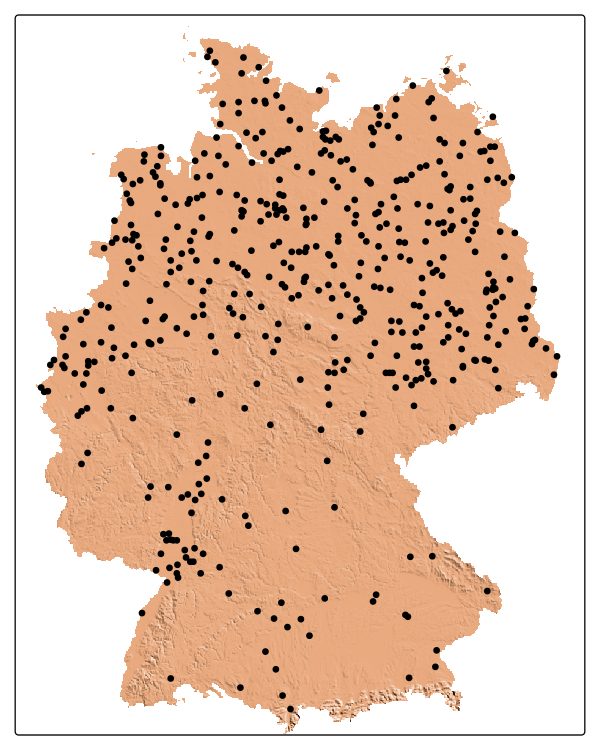
Area of applicability for different sampling designs
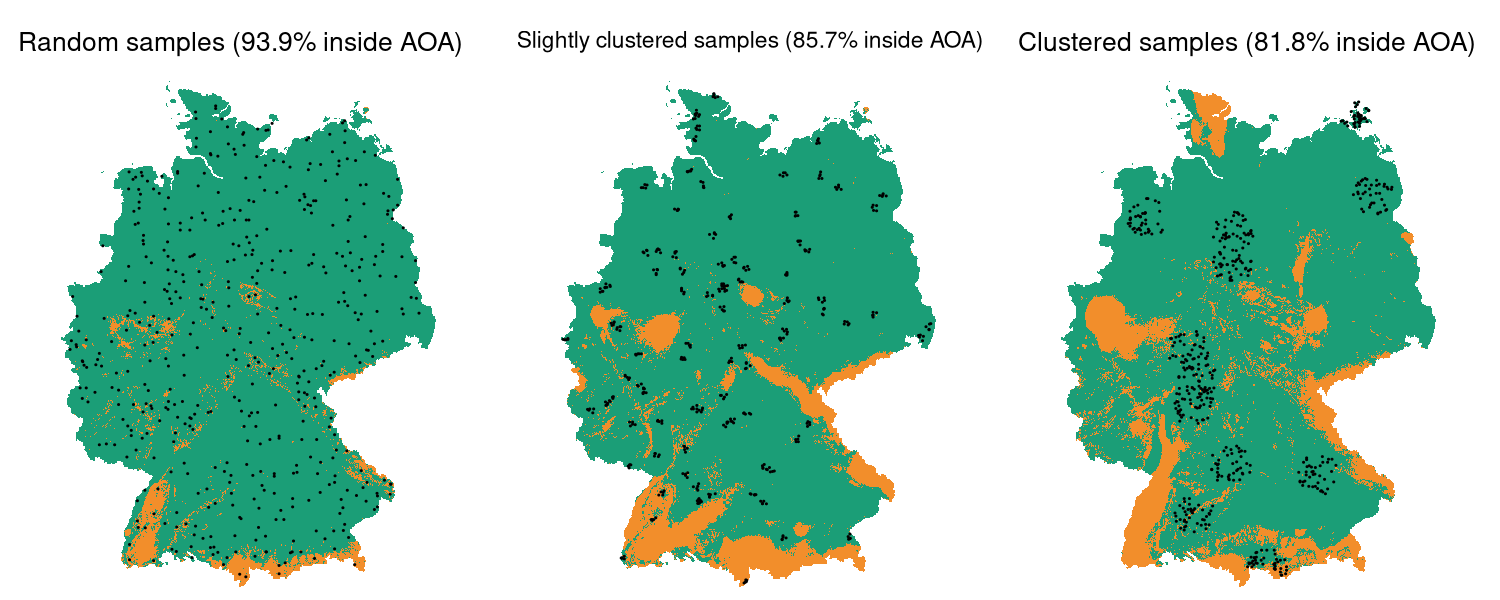
A piece of evidence
Evaluation results for different validation strategies
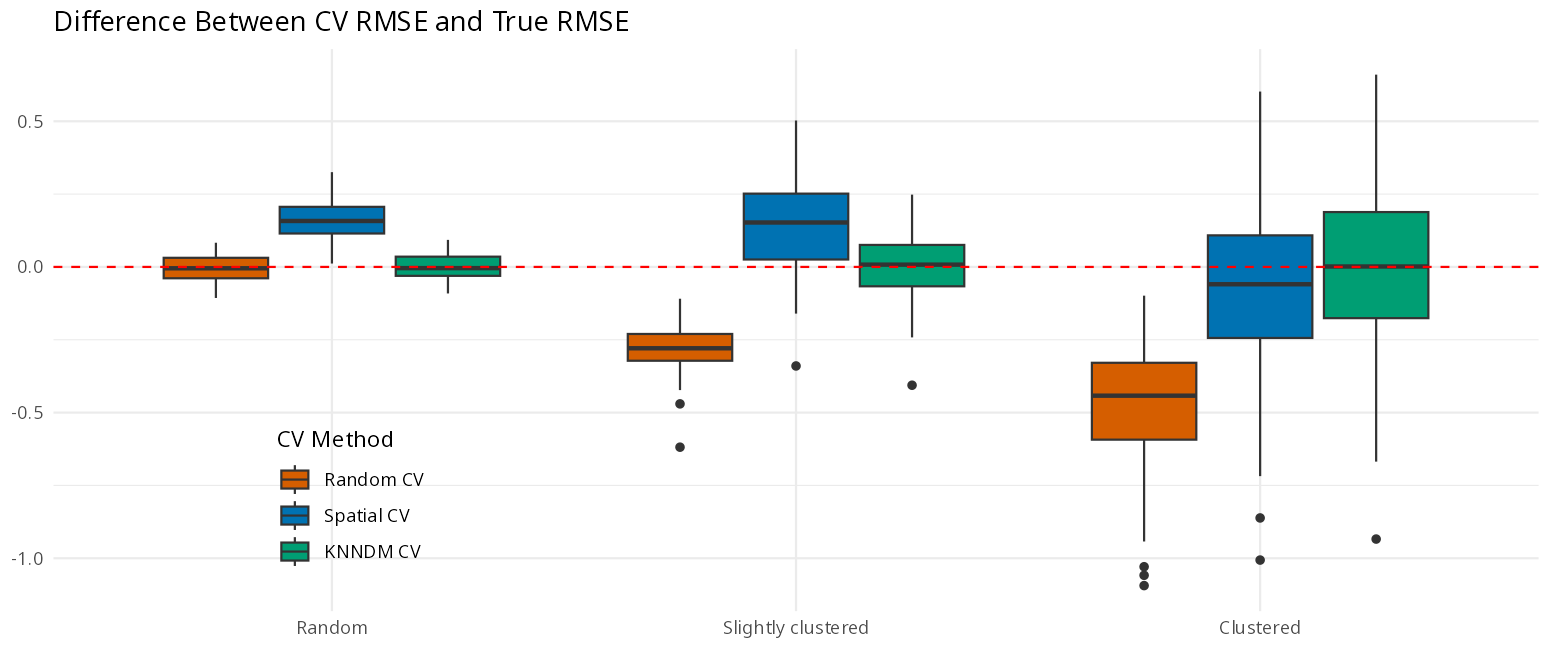
A piece of evidence
Effect of weighting validation points 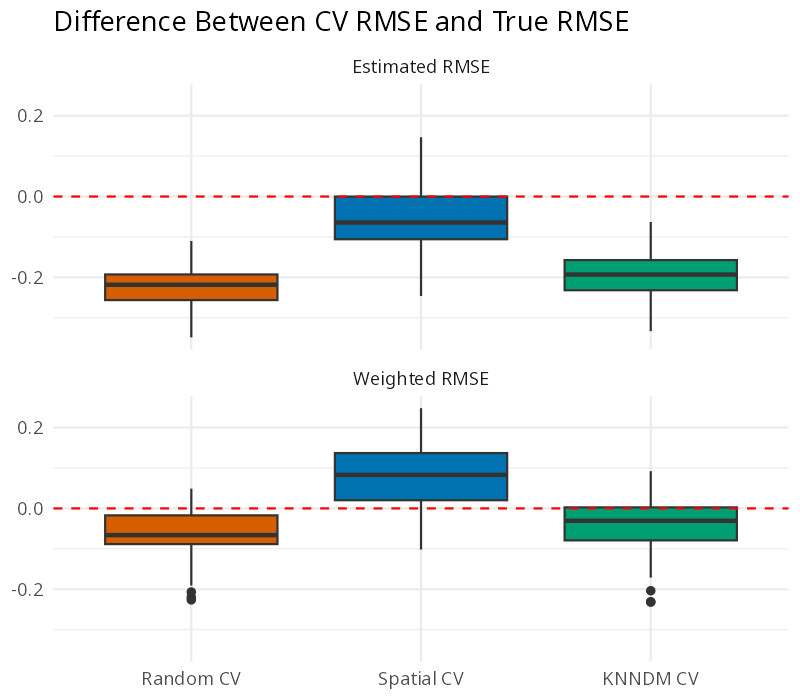
Key components of prediction-domain adaptive evaluation
- Define the prediction domain
- Construct validation folds that reflect the prediction domain
- Weight validation samples by their prevalence in the prediction domain
Open questions remain, including how to mix these three components together.
Also: these are three important components, not a complete theory of spatial ML evaluation.


