
| Arbitrary regions | Context | Outcome | Examples of methods |
|---|---|---|---|
| no | non-spatial | raster | The difference between values of two rasters for each cell |
| no | spatial | raster | Correlation coefficient between focal regions of two rasters; The difference between a focal measure of two rasters (e.g., based on a GLCM-based texture measure (Haralick et al., 1973)); Spatial autocorrelation analysis of the differences (Cliff, 1970); Structural Similarity Index (Robertson et al., 2014; Wang et al., 2004) |
| no | non-spatial | single value | Statistics of the differences between rasters’ values (e.g., RMSE) |
| yes | non-spatial | single value | Dissimilarity between the distributions of two rasters’ values |
| no | spatial | single value | Average of Structural Similarity Index (Robertson et al., 2014; Wang et al., 2004); Complex Wavelet Structural Similarity (Malik and Robertson, 2020; Sampat et al., 2009); Comparison of deep learning-based feature maps using a dissimilarity measure (Malik and Robertson, 2021) |
| yes | spatial | single value | Comparison of deep learning-based feature maps using a dissimilarity measure (Malik and Robertson, 2021) |
| no | non-spatial | multiple values | The distribution of the difference between values of two rasters; Statistics of the differences between rasters’ values (e.g., RMSE) calculated at many scales |
NoteMethods for comparing spatial patterns in raster data
This is the first part of a blog post series on comparing spatial patterns in raster data.
- Part 2: Comparison of spatial patterns in continuous raster data for overlapping regions using R
- Part 3: Comparison of spatial patterns in continuous raster data for arbitrary regions using R
- Part 4: Comparison of spatial patterns in categorical raster data for overlapping regions using R
- Part 5: Comparison of spatial patterns in categorical raster data for arbitrary regions using R
- Part 6: Understanding and extending the methods of comparing spatial patterns in raster data
Comparison of spatial patterns in raster data is a part of many types of spatial analysis. With this task, we want to know how the physical arrangement of observations in one raster differs from the physical arrangement of observations in another raster.
This blog post series will explain the motivation for comparing spatial patterns in raster data, the general considerations when selecting a method for comparison, and the inventory of methods for comparing spatial patterns in raster data. Next, it will show how to use R to compare spatial patterns in continuous and categorical raster data. Lastly, it will discuss the methods’ properties, their applicability, and how they can be extended.
Motivation
In general, four main reasons for comparing spatial patterns in raster data were identified by Long and Robertson (2018, https://doi.org/10.1111/gec3.12356):
- Study of change (i.e., how the spatial pattern of a landscape has changed over time)
- Study of similarity (i.e., how similar the spatial pattern of two landscapes is)
- Study of association (i.e., how the spatial pattern of one theme is associated with the spatial pattern of another theme)
- Spatial model assessment (i.e., how well a model output matches the spatial pattern of the reference data)
For now, I want to focus on the situation in which only two rasters are compared at a time.1 Then, we can think about comparing spatial patterns in raster data as the type of operation that is performed:
- Comparison of the same variable for two different areas
- Comparison of two different variables (or e.g., sensors) for the same area
- Comparison of the same variable for the same area at two different times
Visual inspection
To think about this topic, let’s consider the examples of the Corine Land Cover (CLC) data for Tartu, Estonia in 2000 and 2018, and for Poznan, Poland in 2018:
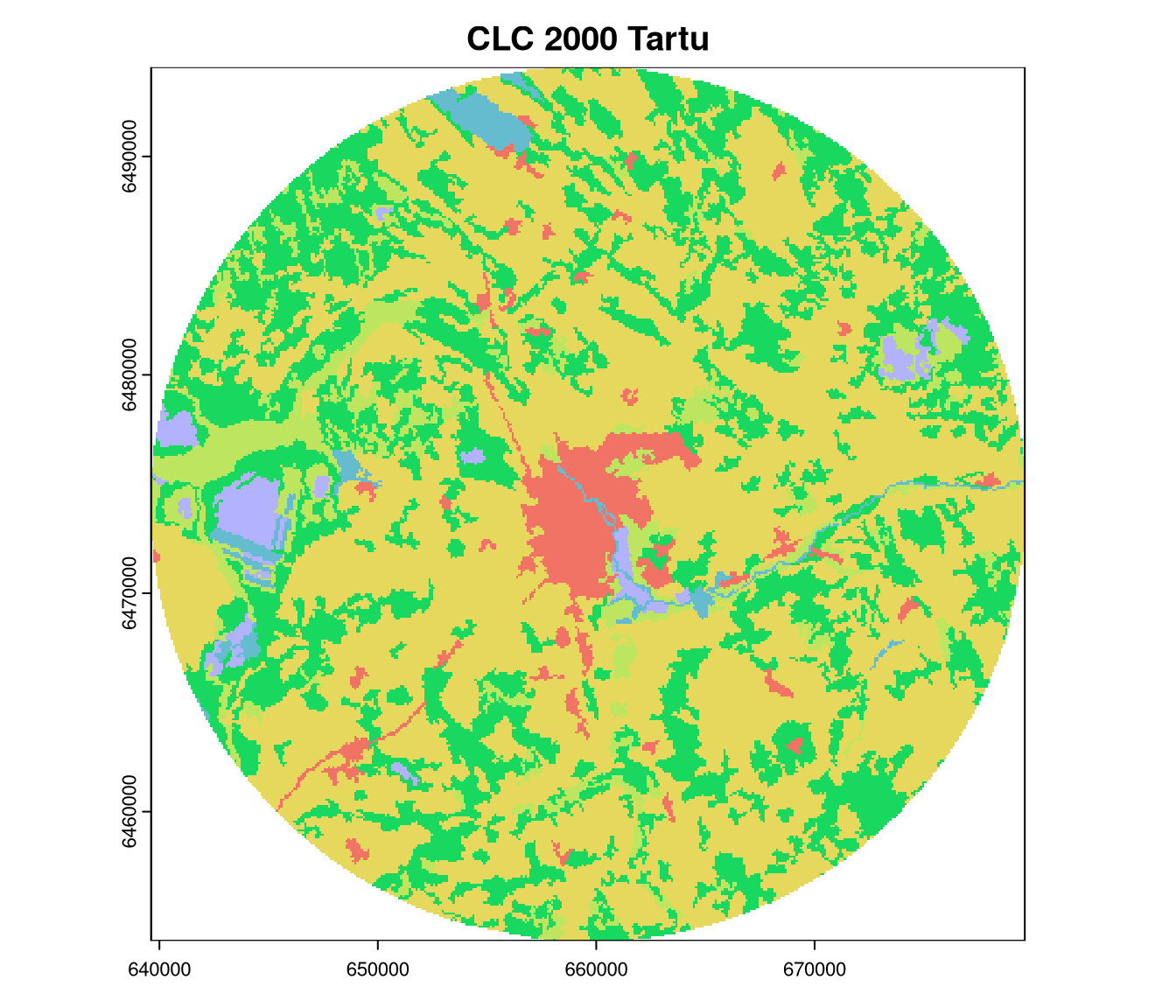
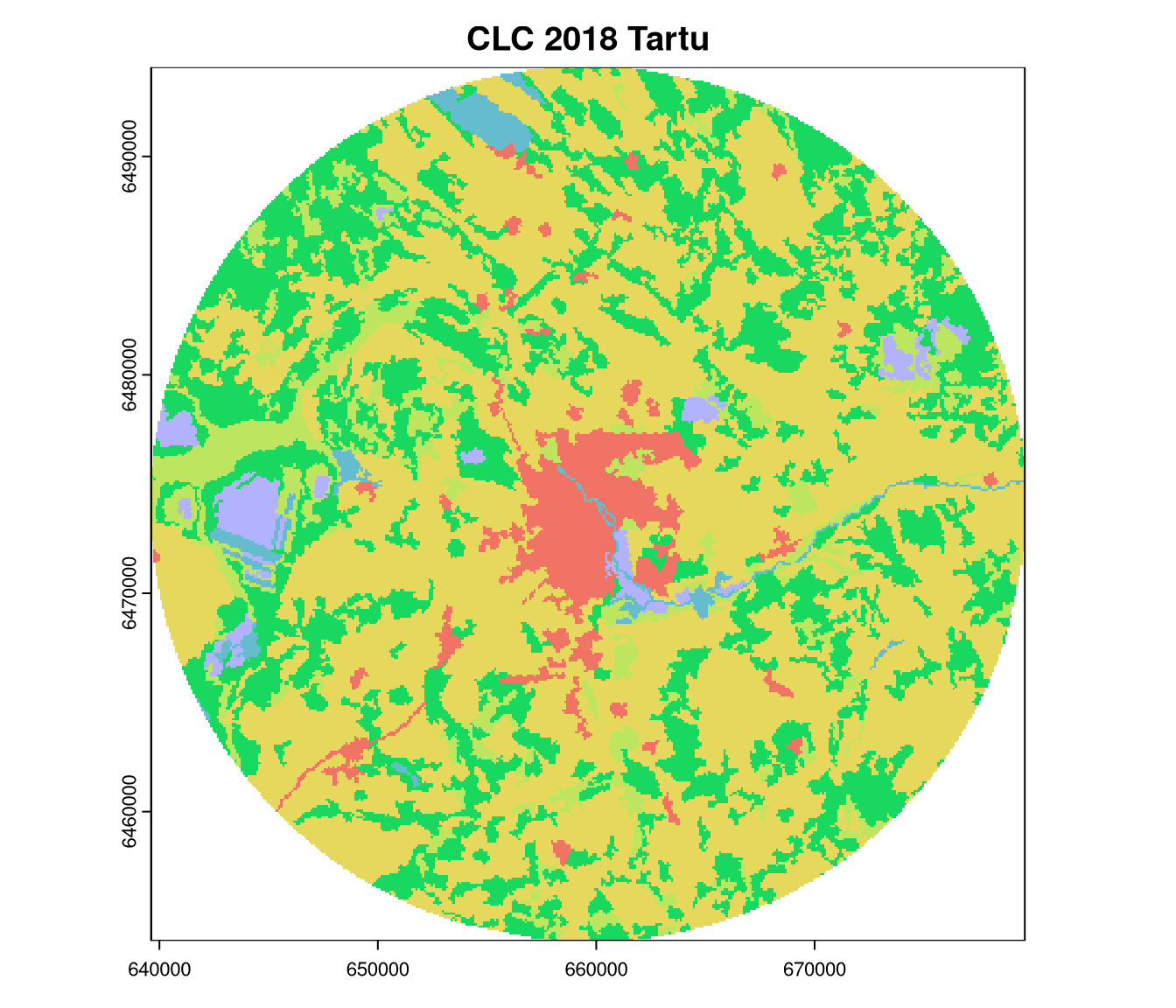
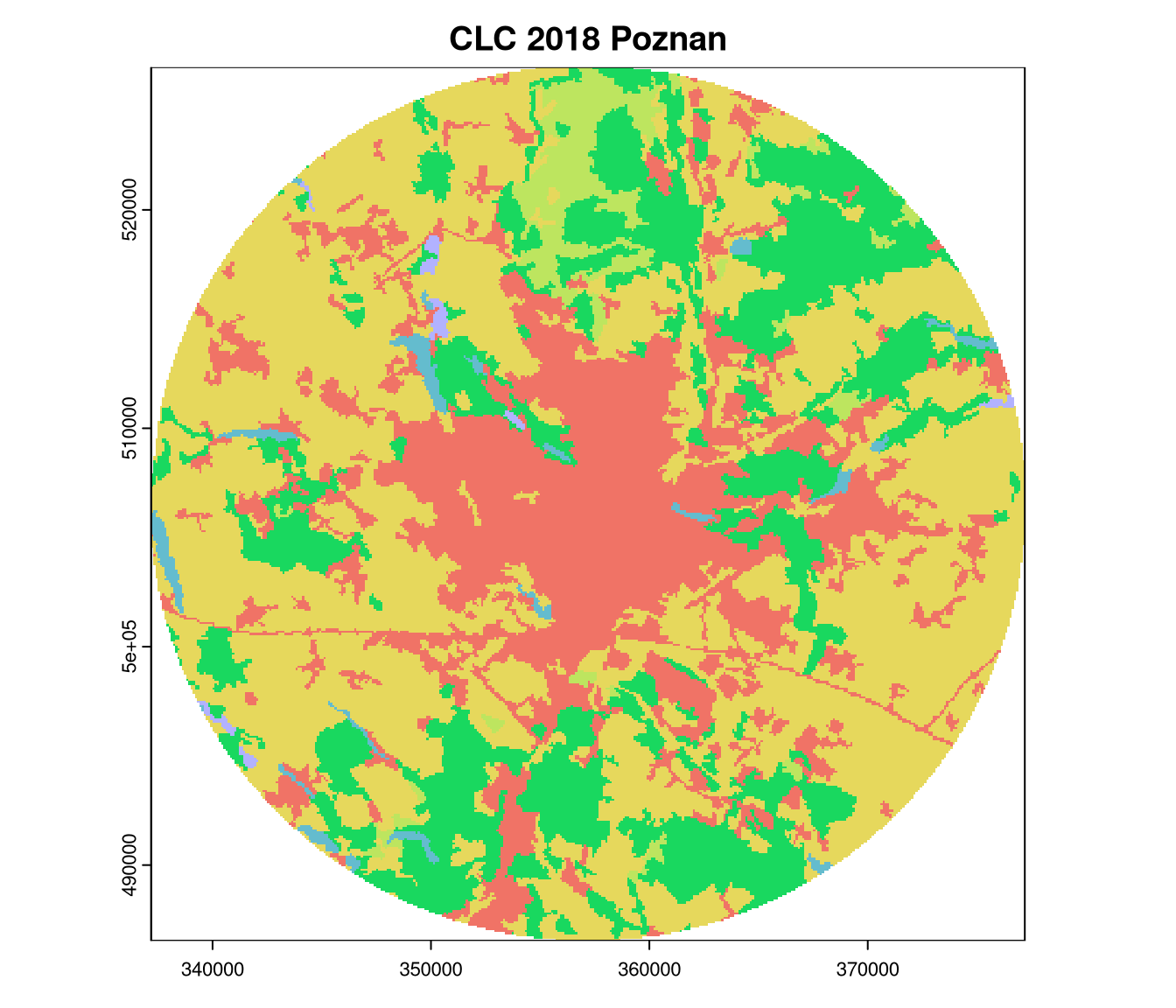
We can start comparing the spatial patterns in these rasters just by looking at them: the land cover for Tartu in 2000 and 2018 looks similar, but it is different for Poznan in 2018 (much more urban areas, less forests). A comparison of Tartu in 2000 and 2018 suggests that urban areas have expanded into areas that were previously mostly covered by agricultural land. Visual inspection is a good starting point, as the human eye can detect multiple patterns that are not easily quantifiable. At the same time, it is subjective and may not be suitable for large datasets.
Generalization of the main aspects to consider
Alternatively, we can use quantitative methods to compare the spatial patterns in these rasters. Figure 1 shows general considerations when thinking about the properties of the methods for comparing spatial patterns in raster data.
flowchart TB
A[Arbitrary regions] ---|Yes| B(Spatial context)
A ---|No| C(Spatial context)
B ---|Yes| D{{Outcome}}
B ---|No| E{{Outcome}}
C ---|Yes| F{{Outcome}}
C ---|No| G{{Outcome}}
D --> H([Single value])
E --> I([Single value])
F --> J([Single value])
F --> K([Multiple values])
F --> L([Raster])
G --> M([Single value])
G --> N([Multiple values])
G --> O([Raster])
style D stroke:transparent
style E stroke:transparent
style F stroke:transparent
style G stroke:transparent
The first main aspect to consider when comparing spatial patterns in raster data is whether or not we are dealing with arbitrary regions. Working on overlapping (i.e., non-arbitrary) regions, e.g., CLC in Tartu in 2000 and 2018, allows for different approaches than working on arbitrary regions, e.g., CLC in Tartu in 2018 and Poznan in 2018. With non-arbitrary regions, each cell in one raster (or each cell in a moving window) can be compared to a corresponding cell in another raster. Thus, one possible outcome of the comparison is another raster, which highlights where the spatial patterns are similar or different. This is not possible with arbitrary regions, and the comparison usually includes spatial patterns of whole rasters.
The second main aspect to consider when comparing spatial patterns in raster data is whether the method used allows the integration of the spatial context of the analysis. A difference between the values of two cells is straightforward to calculate and interpret, but it does not consider the other local values. Alternatively, some methods use the spatial context of the analysis, e.g., by comparing the values in a moving window or a local neighborhood.
It is also worth noting that the comparison of spatial patterns in raster data can result in different types of data. For overlapping regions, the outcome can be a single value, multiple values, or a raster, and for arbitrary regions, it is usually a single value (multiple values are also possible, but often as a collection of single values’ results).
The above considerations can be applied to both continuous and categorical raster data, but the methods used for comparing spatial patterns in these two types of data are different.
Inventory of methods
An inventory of methods for comparing spatial patterns in raster data is presented in the following tables.2 Methods for comparing two layers of spatial continuous raster data are shown in Table 1, and methods for spatial categorical raster data are in Table 2.
| Arbitrary regions | Context | Outcome | Examples of methods |
|---|---|---|---|
| no | non-spatial | raster | The binary difference between two rasters |
| no | spatial | raster | The difference between a focal measure of two rasters (e.g., selected landscape metric); Dissimilarity between spatial signatures of focal regions of two rasters |
| no | non-spatial | single value | The proportion of changed pixels; The overall comparison (Pontius, 2002), A statistic of the differences between rasters’ values |
| yes | non-spatial | single value | Comparison of the values of a non-spatial landscape metric |
| no | spatial | single value | Multiple resolution procedure (Costanza, 1989); Expanding window approach (Kuhnert et al., 2005); Fuzzy Kappa (Hagen-Zanker, 2009); Spatial association between regionalizations using V-measure (Nowosad and Stepinski, 2018) |
| yes | spatial | single value | Comparison of the values of a landscape metric (Turner et al., 1989) or fractal dimensions (Batty and Longley, 1994); Dissimilarity of a spatial signature between two rasters (Jasiewicz and Stepinski, 2013) |
| no | non-spatial | multiple values | The confusion matrix |
| no | spatial | multiple values | Comparison of mutual information spectra (Remmel and Csillag, 2006) |
Both tables are adapted from the “Comparing spatial patterns in raster data using R” paper published in the ISPRS Archives (Nowosad, 2024, https://doi.org/10.5194/isprs-archives-XLVIII-4-W12-2024-127-2024).3 There you can find the complete list of the references for the methods presented in the tables.
In the next blog posts, I will focus on the practical aspects of comparing spatial patterns: how to use R to compare spatial patterns in continuous and categorical raster data. It will include the interpretation of the results and the discussion of the characteristics of the methods. Stay tuned!
Footnotes
I may expand this to the comparison of multiple rasters in a future blog post.↩︎
The tables omit the visual inspection of the data, which is often the first step in the comparison of spatial patterns in raster data.↩︎
However, I decided to use the term “arbitrary regions” instead of “disjoint areas”.↩︎
Reuse
Citation
BibTeX citation:
@online{nowosad2024,
author = {Nowosad, Jakub},
title = {Inventory of Methods for Comparing Spatial Patterns in Raster
Data},
date = {2024-10-13},
url = {https://jakubnowosad.com/posts/2024-10-13-spatcomp-bp1/},
langid = {en}
}
For attribution, please cite this work as:
Nowosad, Jakub. 2024. “Inventory of Methods for Comparing Spatial
Patterns in Raster Data.” October 13. https://jakubnowosad.com/posts/2024-10-13-spatcomp-bp1/.