
library(gdalUtils)
dir.create("data")
# downloading the land cover data
download.file("https://github.com/Nowosad/lsm-bp1/raw/master/data/cci_lc_australia.zip",
destfile = "data/cci_lc_australia.zip")
# unziping the file
unzip("data/cci_lc_australia.zip", "data/cci_lc_australia.tif")
# reprojecting the raster data to a local projected coordinate reference system
# read more at http://spatialreference.org/ref/epsg/gda94-australian-albers/
gdalwarp(srcfile = "data/cci_lc_australia.tif",
dstfile = "data/cci_lc_australia_aea.vrt",
of = "VRT",
t_srs = "+proj=aea +lat_1=-18 +lat_2=-36 +lat_0=0 +lon_0=132 +x_0=0 +y_0=0 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs")
# compressing the output file
gdal_translate(src_dataset = "data/cci_lc_australia_aea.vrt",
dst_dataset = "data/cci_lc_australia_aea.tif",
co = "COMPRESS=LZW")Landscape metrics are algorithms that quantify physical characteristics of landscape mosaics (aka categorical raster) in order to connect them to some ecological processes. Many different landscape metrics exist and they can provide three main levels of information: (i) landscape level, (ii) class level, and (iii) patch level. A landscape level metric gives just one value describing a certain property of a landscape mosaic, such as its diversity. A class level metric returns one value for each class (category) present in a landscape. A patch level metric separates neighboring cells belonging to the same class, and calculates a value for each patch.1
Landscape metrics are often applied to better understand a landscape structure around some sampling points. In this post, I show how to prepare input data and how to calculate selected landscape metrics based on different buffer sizes and shapes. All calculations were performed in R, using gdalUtils, sf, and raster packages for spatial data handling, purrr to ease some calculations, and most importantly the landscapemetrics package was used to calculate landscape metrics.
Data preparation
Every software for calculations of landscape metrics, such as FRAGSTATS or landscapemetrics, expects the input data in a projected coordinate reference system instead of a geographic coordinate reference system. This is due to a fact that geographic coordinate reference systems are expressed in degrees, and one degree on the equator has a different length in meters than one degree on a middle latitude. Projected coordinate reference systems, on the other hand, have a linear unit of measurement such as meters. This allows for proper calculations of distances or areas.2
In this case, the input datasets (cci_lc_australia.tif and sample_points.csv) are in a geographic coordinate reference system called WGS84. Therefore, it is important to reproject the data before calculating any landscape metrics. Reprojection of raster objects is possible with an R package called gdalUtils:
Reading and reprojecting vector (points) objects can be done with the sf package:
library(sf)
# downloading the points
download.file("https://raw.githubusercontent.com/Nowosad/lsm-bp1/master/data/sample_points.csv",
destfile = "data/sample_points.csv")
# reading the point data and reprojecting it
points = read.csv("data/sample_points.csv") %>%
st_as_sf(coords = c("longitude", "latitude")) %>%
st_set_crs(4326) %>%
st_transform("+proj=aea +lat_1=-18 +lat_2=-36 +lat_0=0 +lon_0=132 +x_0=0 +y_0=0 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs ")
# saving the new object to a spatial data format GPKG
st_write(points, "data/sample_points.gpkg")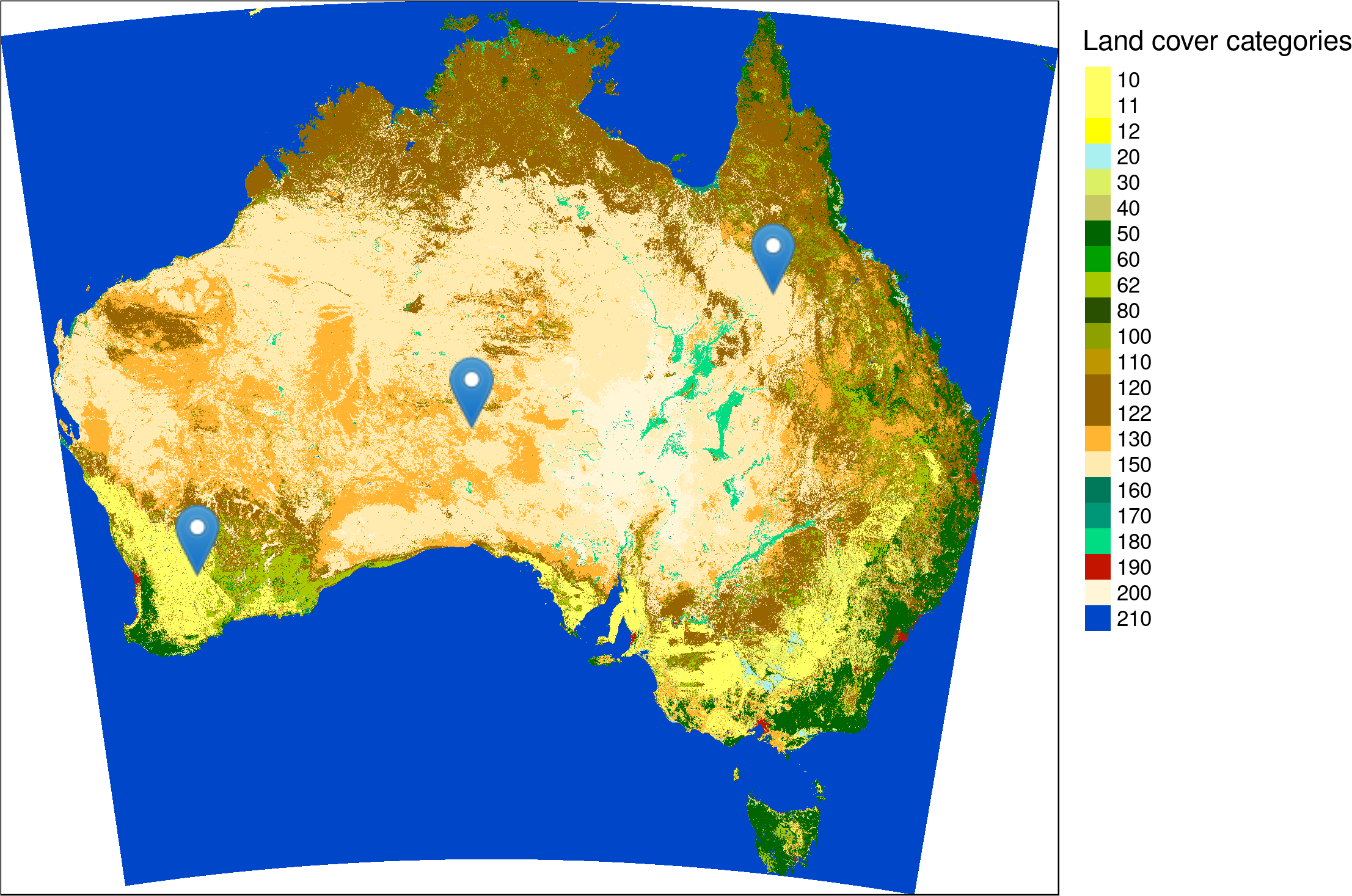
Location of three sample points on a land cover map of Australia. Source of the input map: https://maps.elie.ucl.ac.be/CCI/viewer/
Calculations of landscape metrics in a buffer
Now, we can read the new files - the new raster with the raster() function and the new points file with the st_read() function:
# attaching the packages used in the next examples
library(raster)
library(sf)
library(purrr)
library(landscapemetrics)
# reading the raster and vector datasets
lc = raster("data/cci_lc_australia_aea.tif")
sample_points = st_read("data/sample_points.gpkg", quiet = TRUE)The landscapemetrics package has a function designed for calculations of landscape metrics for a given buffer. It is called sample_lsm() and it expects, at least three input arguments - a raster, a vector (points), and a buffer size. As a default, it calculates all of the available metrics in a square buffer, where buffer size is the side-length in map units (e.g. meters).
square_all = sample_lsm(lc,
y = sample_points,
size = 3000)
square_all## # A tibble: 1,282 x 8
## layer level class id metric value plot_id percentage_inside
## <int> <chr> <int> <int> <chr> <dbl> <int> <dbl>
## 1 1 class 11 NA ai 92.1 1 109.
## 2 1 class 100 NA ai 100 1 109.
## 3 1 class 122 NA ai NA 1 109.
## 4 1 class 130 NA ai 50 1 109.
## 5 1 class 150 NA ai 71.1 1 109.
## 6 1 class 11 NA area_cv NA 1 109.
## 7 1 class 100 NA area_cv NA 1 109.
## 8 1 class 122 NA area_cv NA 1 109.
## 9 1 class 130 NA area_cv 33.3 1 109.
## 10 1 class 150 NA area_cv 119. 1 109.
## # … with 1,272 more rowsThe output, square_all, is a data frame containing values of all of the landscape metrics available in the landscapemetrics package. The structure of the output is stable and contains the following columns:
layer- id of the input raster (landscape). It is possible to calculate landscape metrics on several rasters at the same time.level- a landscape metrics level (“landscape”, “class”, or “patch”).class- a number of a class for class and patch level metrics.id- a number of a patch for patch level metrics.metric- a metric name.value- an output value of the metric.plot_id- id of the input vector (point).percentage_inside- the size of the actual sampled landscape in %. It is not always 100% due to two reasons: (i) clipping raster cells using a buffer not directly intersecting a raster cell center lead to inaccuracies and (ii) sample plots can exceed the landscape boundary.
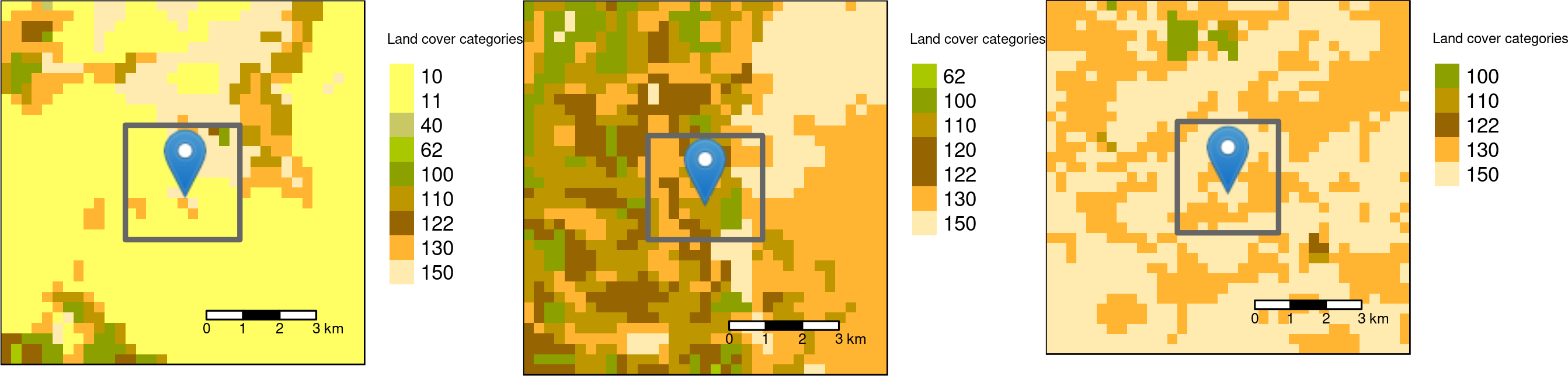
Square buffers with the side-length of 3000 meters around the three sample points.
The sample_lsm() function also allows for selecting metrics using a level name ("landscape", "class", or "patch"), a metric abbreviation, full name of a metric, or a metric type. For example, SHDI (Shannon’s diversity index) on a landscape level ("lsm_l_shdi") can be calculated using the code below.
square_shdi = sample_lsm(lc,
y = sample_points,
size = 3000,
what = "lsm_l_shdi")
square_shdi## # A tibble: 3 x 8
## layer level class id metric value plot_id percentage_inside
## <int> <chr> <int> <int> <chr> <dbl> <int> <dbl>
## 1 1 landscape NA NA shdi 0.870 1 109.
## 2 1 landscape NA NA shdi 1.49 2 98.9
## 3 1 landscape NA NA shdi 0.665 3 98.9The result shows that the area around the second sample point is the most diverse (SHDI value of 1.49), and the area around the third sample point is the least diverse (SHDI value of 0.665).
As the default, sample_lsm() uses a square buffer, but it could be changed to a circle one with the shape argument set to "circle". In this case, the size argument represents the radius in map units.
circle_shdi = sample_lsm(lc,
y = sample_points,
size = 3000,
what = "lsm_l_shdi",
shape = "circle")
circle_shdi## # A tibble: 3 x 8
## layer level class id metric value plot_id percentage_inside
## <int> <chr> <int> <int> <chr> <dbl> <int> <dbl>
## 1 1 landscape NA NA shdi 1.03 1 99.6
## 2 1 landscape NA NA shdi 1.65 2 100.
## 3 1 landscape NA NA shdi 0.689 3 99.9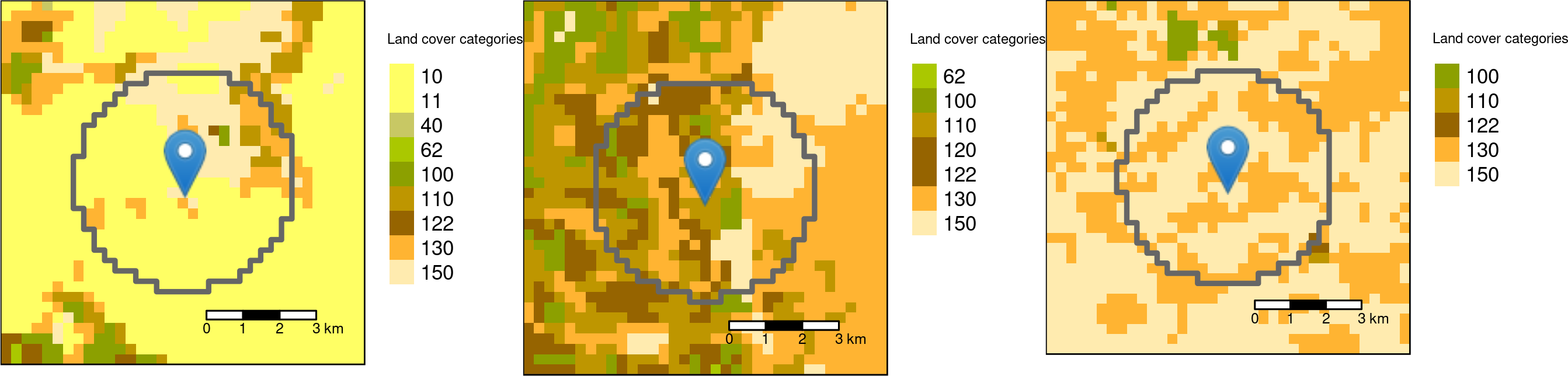
Circle buffers with the radius of 3000 meters around the three sample points.
Calculations of landscape metrics for many buffers
Finally, it is also possible to calculate landscape metrics on many different buffer sizes at the same time. You just need to select what sizes you are interested in and use the sample_lsm() function inside a map_dfr() function.
# creating buffers of 3000 and 6000 meters
sizes = c(3000, 6000)
# calculating shdi (landscape metric) for each buffer
two_sizes_output = sizes %>%
set_names() %>%
map_dfr(~sample_lsm(lc, y = sample_points, what = "lsm_l_shdi", size = .),
.id = "buffer")It calculates all of the selected metrics for all of the buffers.
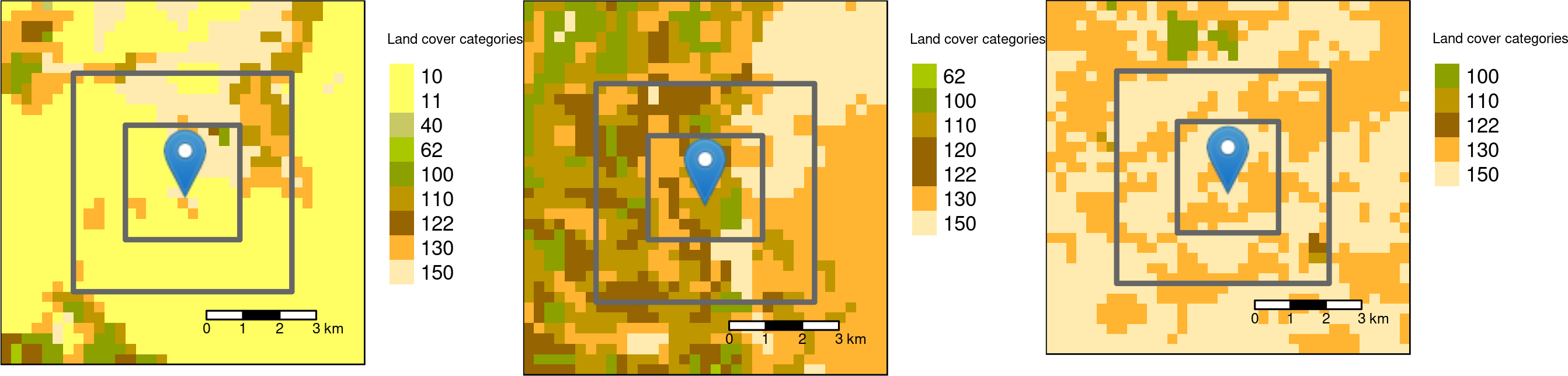
Square buffers with the side-length of 3000 and 6000 meters around the three sample points.
The result is a data frame, where the first column describes the buffer size, and the rest is a standard landscapemetrics output.
two_sizes_output## # A tibble: 6 x 9
## buffer layer level class id metric value plot_id percentage_inside
## <chr> <int> <chr> <int> <int> <chr> <dbl> <int> <dbl>
## 1 3000 1 landscape NA NA shdi 0.870 1 109.
## 2 3000 1 landscape NA NA shdi 1.49 2 98.9
## 3 3000 1 landscape NA NA shdi 0.665 3 98.9
## 4 6000 1 landscape NA NA shdi 1.02 1 99.1
## 5 6000 1 landscape NA NA shdi 1.62 2 99.1
## 6 6000 1 landscape NA NA shdi 0.731 3 99.1Summary
This post gave a few examples of how to calculate selected landscape metrics for buffers around sampling points using the landscapemetrics package and its function sample_lsm(). In the same time, the landscapemetrics package has much more to offer, including a lot of implemented landscape metrics, a number of utility functions (e.g. extract_lsm() or get_patches()), and several C++ functions designed for the development of new metrics.
The landscapemetrics is also an open-source collaborative project. It enables community contributions, including documentation improvements, bug reports, and ideas to add new metrics and functions. To learn more you can visit the package website at https://r-spatialecology.github.io/landscapemetrics/ or read the Ecography article.
Footnotes
For a more detailed explanation see https://r-spatialecology.github.io/landscapemetrics/articles/articles/general-background.html.↩︎
More information about coordinate reference systems can be found at https://geocompr.robinlovelace.net/spatial-class.html#crs-intro.↩︎
Reuse
Citation
BibTeX citation:
@online{nowosad2019,
author = {Nowosad, Jakub},
title = {Efficient Landscape Metrics Calculations for Buffers Around
Sampling Points},
date = {2019-03-07},
url = {https://jakubnowosad.com/posts/2019-03-07-lsm-bp1/},
langid = {en}
}
For attribution, please cite this work as:
Nowosad, Jakub. 2019. “Efficient Landscape Metrics Calculations
for Buffers Around Sampling Points.” March 7. https://jakubnowosad.com/posts/2019-03-07-lsm-bp1/.