
# 1. Extract the non-missing values from the rasters
values1 = na.omit(values(ndvi2023_tartu)[, 1])
values2 = na.omit(values(ndvi2023_poznan)[, 1])
# 2. Scale the values to the range of 0 to 1
values1_rescaled = (values1 - min(values1)) / (max(values1) - min(values1))
values2_rescaled = (values2 - min(values2)) / (max(values2) - min(values2))
# 3. Bin the values to create histograms
bin_edges = seq(0, 1, length.out = 33)
hist1 = hist(values1_rescaled, breaks = bin_edges, plot = FALSE)
hist2 = hist(values2_rescaled, breaks = bin_edges, plot = FALSE)
# 4. Normalize the histogram counts to get probability distributions
prob1 = hist1$counts / sum(hist1$counts)
prob2 = hist2$counts / sum(hist2$counts)
NoteMethods for comparing spatial patterns in raster data
This is the third part of a blog post series on comparing spatial patterns in raster data. More information about the whole series can be found in part one.
This blog post focuses on the comparison of spatial patterns in continuous raster data for arbitrary regions. Thus, the shown methods require two continuous rasters, which may have different extents, resolutions, etc. The outcome of such comparisons is, most often, a single value, which indicates the difference/similarity between the spatial patterns of the two rasters.
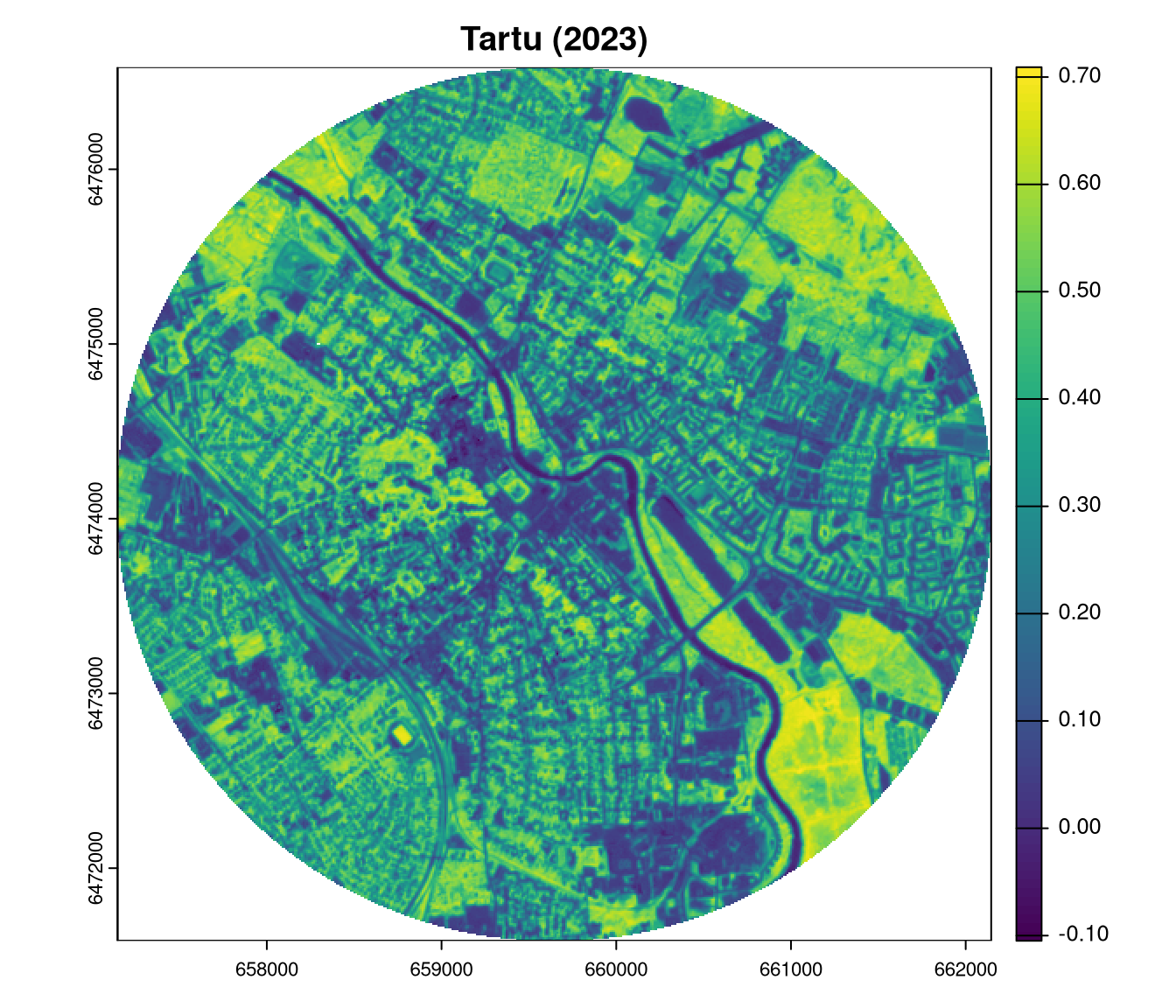
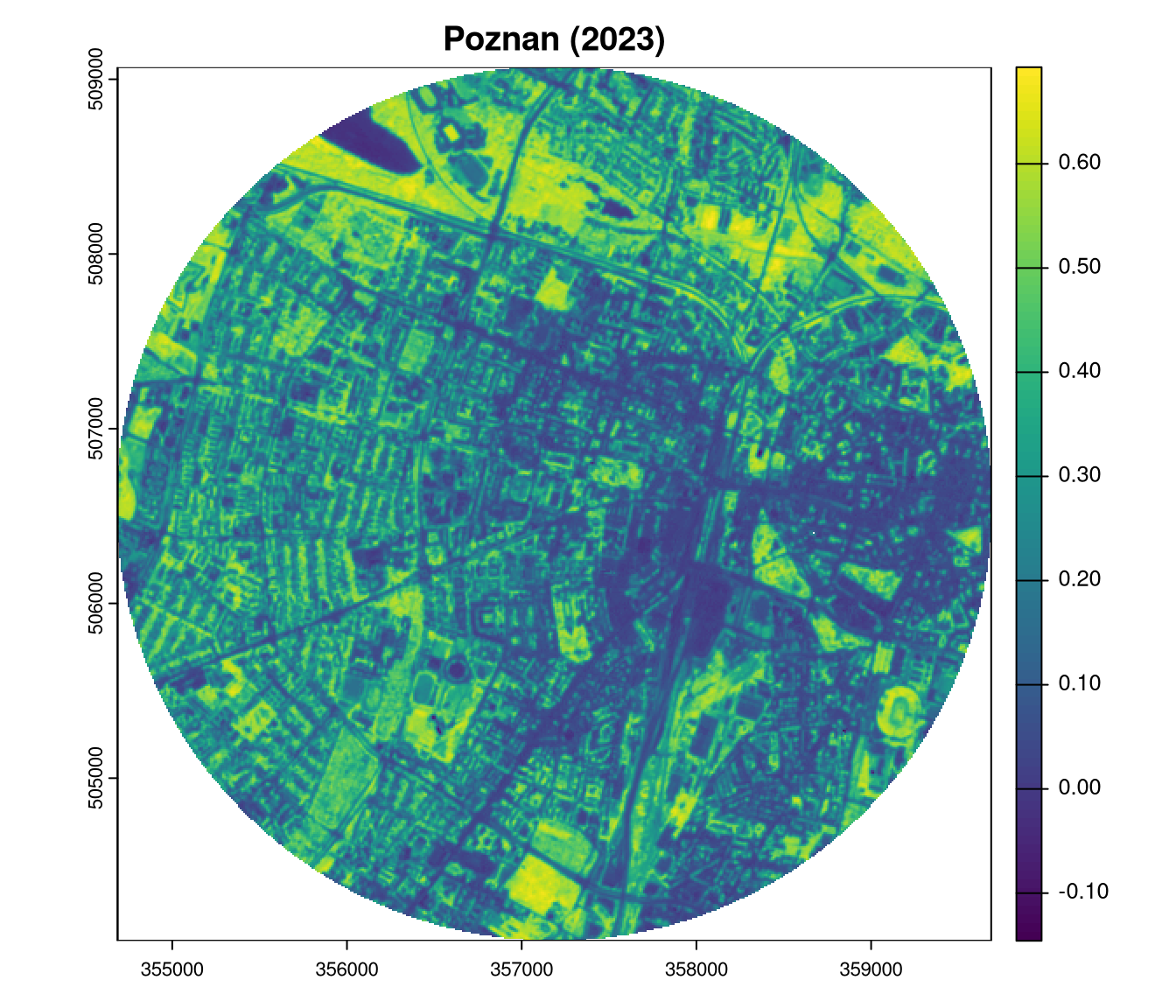
Three continuous raster datasets are used in this blog post: the Normalized Difference Vegetation Index (NDVI) datasets for Tartu (Estonia) for the years 2018 and 2023, and Poznań (Poland) for the year 2023.
library(terra)
ndvi2018_tartu = rast("https://github.com/Nowosad/comparing-spatial-patterns-2024/raw/refs/heads/main/data/ndvi2018_tartu.tif")
ndvi2023_tartu = rast("https://github.com/Nowosad/comparing-spatial-patterns-2024/raw/refs/heads/main/data/ndvi2023_tartu.tif")
ndvi2023_poznan = rast("https://github.com/Nowosad/comparing-spatial-patterns-2024/raw/refs/heads/main/data/ndvi2023_poznan.tif")
plot(ndvi2018_tartu, main = "Tartu (2018)")
plot(ndvi2023_tartu, main = "Tartu (2023)")
plot(ndvi2023_poznan, main = "Poznan (2023)")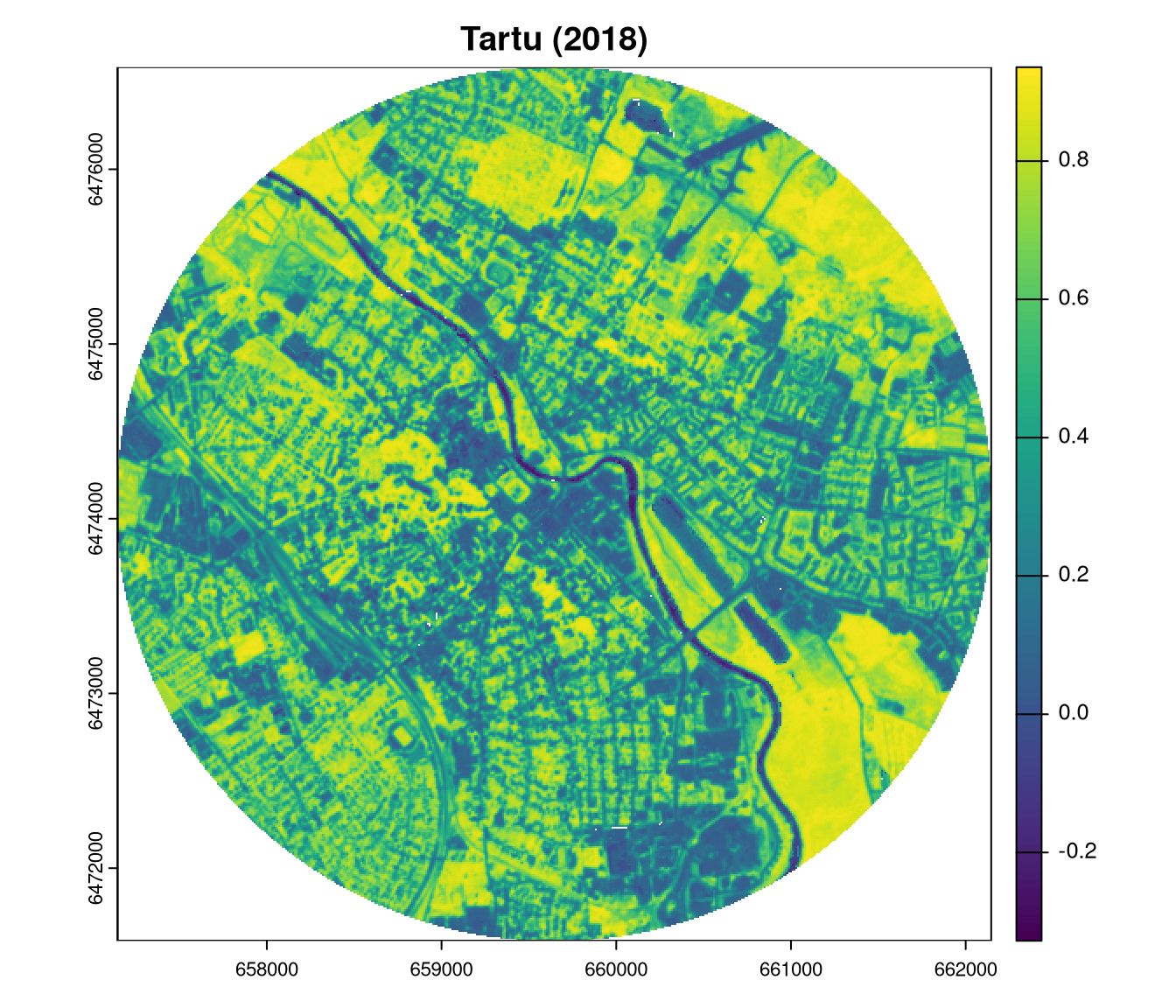
Non-spatial context
Single value outcome
Disimilarity between the distributions of two rasters’ values
Rasters consist of values, and thus, it seems possible to compare the distributions of these values. However, it may not be straightforward as they may have different lengths, ranges, etc. There are many possible ways to create distributions from rasters, but here I show just one:
- Extract the non-missing values from the rasters.
- Rescale the values to the range of 0 to 1.
- Bin the values to create histograms.
- Normalize the histogram counts to get probability distributions.
Importantly, the above approach involves many decisions, for example, should we use the minimum and maximum values of both rasters or each separately; how many bins should we use; etc.
Next, we can calculate the dissimilarity between the two distributions, for example, using the Kullback-Leibler divergence implemented in the philentropy package (HG 2018).1
philentropy::distance(rbind(prob1, prob2), method = "kullback-leibler")kullback-leibler
0.1033112 Lower values of the Kullback-Leibler divergence suggest that the distributions are more similar.
The above approach can be generalized with just one modification – the maximum and minimum values are external parameters.
get_min_max = function(rast_list){
min_v = min(vapply(rast_list,
FUN = function(r) min(na.omit(values(r)[, 1])),
FUN.VALUE = numeric(1)))
max_v = max(vapply(rast_list,
FUN = function(r) max(na.omit(values(r)[, 1])),
FUN.VALUE = numeric(1)))
return(c(min_v, max_v))
}
prepare_hist = function(r, min_v, max_v){
values_r = na.omit(values(r)[, 1])
values_r_rescaled = (values_r - min_v) / (max_v - min_v)
bin_edges = seq(0, 1, length.out = 33) # 32 bins
hist_r = hist(values_r_rescaled, breaks = bin_edges, plot = FALSE)
prob_r = hist_r$counts / sum(hist_r$counts)
return(prob_r)
}
min_max = get_min_max(list(ndvi2018_tartu, ndvi2023_tartu, ndvi2023_poznan))
tartu2018_hist = prepare_hist(ndvi2018_tartu, min_max[1], min_max[2])
tartu2023_hist = prepare_hist(ndvi2023_tartu, min_max[1], min_max[2])
poznan2023_hist = prepare_hist(ndvi2023_poznan, min_max[1], min_max[2])
philentropy::distance(rbind(tartu2018_hist, tartu2023_hist, poznan2023_hist),
method = "kullback-leibler") v1 v2 v3
v1 0.000000 2.48398816 2.65464473
v2 2.483988 0.00000000 0.08389761
v3 2.654645 0.08389761 0.00000000The results suggest that the distributions of NDVI values for Tartu and Poznan in 2023 are more similar to each other than to the distribution of NDVI values for Tartu in 2018.
As a bonus, we can visualize the histograms of the NDVI values for the three rasters.
df_hist = data.frame(
values = c(tartu2018_hist, tartu2023_hist, poznan2023_hist),
group = rep(c("Tartu 2018", "Tartu 2023", "Poznan 2023"), each = 32),
bin = rep(1:32, 3))
library(ggplot2)
ggplot(df_hist, aes(x = bin, y = values, color = group)) +
geom_line() +
theme_minimal()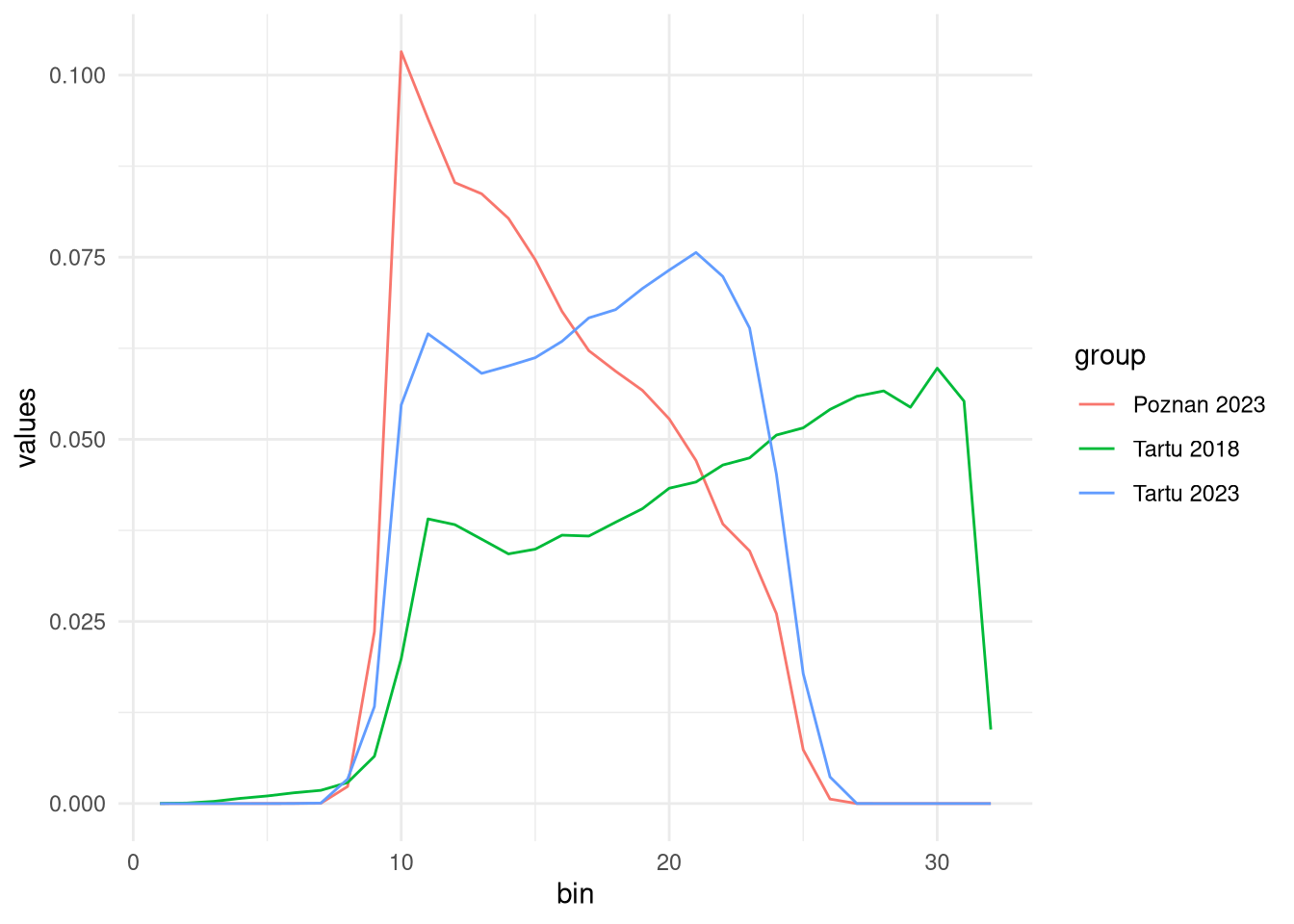
Spatial context
Single value outcome
The difference between an average of a focal measure of two rasters
To include the spatial context in the comparison of continuous raster data, we can use focal measures.
The geodiv package (Smith et al. 2023) provides more than a dozen of functions to calculate surface metrics for continuous rasters. One of them is the surface roughness (sa()) function, which calculates the absolute deviation of raster value heights from the mean value.
library(geodiv)
ndvi2018_tartu_sa = sa(ndvi2018_tartu) # 0.219
ndvi2023_tartu_sa = sa(ndvi2023_tartu) # 0.150
ndvi2023_poznan_sa = sa(ndvi2023_poznan) # 0.141
abs(ndvi2023_tartu_sa - ndvi2018_tartu_sa)[1] 0.06886273abs(ndvi2023_poznan_sa - ndvi2018_tartu_sa)[1] 0.07695052abs(ndvi2023_poznan_sa - ndvi2023_tartu_sa)[1] 0.008087792The absolute differences show that the NDVI values for Tartu in 2023 have much more similar variability to the NDVI values for Poznan in 2023 than to the NDVI values for Tartu in 2018. On the other hand, the calculation of the differences could reveal the direction of the change, e.g., if the NDVI values for Tartu in 2023 are more or less variable than in 2018.
Another example of calculating and then comparing focal measures is the calculation of one of the GLCM texture metrics and then comparing the outcome values. Here, we compute the average of the homogeneity metric, which values are higher for more homogeneous textures, using the GLCMTextures package (Ilich 2020). Next, we calculate the absolute differences between the mean homogeneity values for the three rasters.
library(GLCMTextures)
ndvi2018_tartu_hom = glcm_textures(ndvi2018_tartu, n_levels = 16, shift = c(1, 0),
metric = "glcm_homogeneity", quantization = "equal prob")
ndvi2023_tartu_hom = glcm_textures(ndvi2023_tartu, n_levels = 16, shift = c(1, 0),
metric = "glcm_homogeneity", quantization = "equal prob")
ndvi2023_poznan_hom = glcm_textures(ndvi2023_poznan, n_levels = 16, shift = c(1, 0),
metric = "glcm_homogeneity", quantization = "equal prob")
ndvi2018_tartu_homv = global(ndvi2018_tartu_hom, "mean", na.rm = TRUE)
ndvi2023_tartu_homv = global(ndvi2023_tartu_hom, "mean", na.rm = TRUE)
ndvi2023_poznan_homv = global(ndvi2023_poznan_hom, "mean", na.rm = TRUE)
abs(ndvi2023_tartu_homv - ndvi2018_tartu_homv) mean
glcm_homogeneity 0.01857073abs(ndvi2023_poznan_homv - ndvi2018_tartu_homv) mean
glcm_homogeneity 0.02247696abs(ndvi2023_poznan_homv - ndvi2023_tartu_homv) mean
glcm_homogeneity 0.003906225The results show that the NDVI rasters for Tartu in 2023 and Poznan in 2023 have more similar homogeneity than the NDVI raster for Tartu in 2018.
Comparison of the values of the Boltzmann entropy of a landscape gradient (Gao and Li 2019)
Both, the surface roughness and the homogeneity metrics represent a given aspect of the spatial pattern of the continuous raster data. Alternatively, we can want to consider the complexity of the spatial pattern of the continuous raster data as a whole. This may be done using Gao’s entropy metric, which is based on aggregating the values of the input raster, and then calculating the possible ways to disaggregate the new raster into the original one (Gao and Li 2019).
The below example uses the bespatial package (Nowosad 2024).
library(bespatial)
ndvi2018_tartu_bes = bes_g_gao(ndvi2018_tartu, method = "hierarchy", relative = TRUE)
ndvi2023_tartu_bes = bes_g_gao(ndvi2023_tartu, method = "hierarchy", relative = TRUE)
ndvi2023_poznan_bes = bes_g_gao(ndvi2023_poznan, method = "hierarchy", relative = TRUE)
abs(ndvi2023_tartu_bes$value - ndvi2018_tartu_bes$value)[1] 15402.11abs(ndvi2023_poznan_bes$value - ndvi2018_tartu_bes$value)[1] 26013.8abs(ndvi2023_tartu_bes$value - ndvi2023_poznan_bes$value)[1] 10611.69The results show that the NDVI rasters for Tartu in 2023 and Poznan in 2023 have more similar Gao entropy than the NDVI raster for Tartu in 2018.
Comparison of deep learning-based feature maps using a dissimilarity measure
Fairly recent advances in deep learning have enabled the extraction of feature maps from pre-trained models. These feature maps can be used to compare the spatial patterns of continuous raster data (Malik and Robertson 2021).
This example uses the keras3 (Kalinowski et al. 2024) and philentropy (HG 2018) packages. First, the NDVI rasters are normalized to the range of 0 to 1 and converted to a matrix format. Then, they are reshaped to the format required by the VGG16 model: a 3D array with three channels. The VGG16 model is loaded in the next step, and the feature maps are extracted. Finally, the first feature maps are reshaped to a vector format and compared using the Euclidean distance.
library(keras3)
library(philentropy)
# keras3::install_keras(backend = "tensorflow")
normalize_raster = function(r) {
min_val = terra::global(r, "min", na.rm = TRUE)[[1]]
max_val = terra::global(r, "max", na.rm = TRUE)[[1]]
r = terra::app(r, fun = function(x) (x - min_val) / (max_val - min_val))
return(r)
}
ndvi2023n_tartu = normalize_raster(ndvi2023_tartu)
ndvi2023n_poznan = normalize_raster(ndvi2023_poznan)
ndvi2023_tartu_mat = as.matrix(ndvi2023n_tartu, wide = TRUE)
ndvi2023_poznan_mat = as.matrix(ndvi2023n_poznan, wide = TRUE)
ndvi2023_tartu_mat = array(rep(ndvi2023_tartu_mat, 3),
dim = c(nrow(ndvi2023_tartu_mat), ncol(ndvi2023_tartu_mat), 3))
ndvi2023_poznan_mat = array(rep(ndvi2023_poznan_mat, 3),
dim = c(nrow(ndvi2023_poznan_mat), ncol(ndvi2023_poznan_mat), 3))
model = keras3::application_vgg16(weights = "imagenet", include_top = FALSE,
input_shape = c(nrow(ndvi2023_tartu_mat),
ncol(ndvi2023_tartu_mat), 3))
ndvi2023_tartu_mat = keras3::array_reshape(ndvi2023_tartu_mat,
c(1, dim(ndvi2023_tartu_mat)))
ndvi2023_poznan_mat = keras3::array_reshape(ndvi2023_poznan_mat,
c(1, dim(ndvi2023_poznan_mat)))
features2023_tartu = predict(model, ndvi2023_tartu_mat, verbose = 0)
features2023_poznan = predict(model, ndvi2023_poznan_mat, verbose = 0)
# [1, height, width, layer]
feature_map_tartu_1 = as.vector(features2023_tartu[1, , , 1])
feature_map_poznan_1 = as.vector(features2023_poznan[1, , , 1])
distance(rbind(feature_map_tartu_1, feature_map_poznan_1))euclidean
7.007962 The similarity index (CQ) based on the co-dispersion coefficient
The SpatialPack package (Vallejos et al. 2020) provides the CQ() function, which calculates the similarity index based on the co-dispersion coefficient. However, this function (1) requires the input data to be in the matrix format, and (2) does not work with missing values. Thus, the code chunk below has not been evaluated, but it shows how to use the CQ() function for data fulfilling these requirements.
library(SpatialPack)
ndvi2023_tartu_mat = as.matrix(ndvi2023_tartu, wide = TRUE)
ndvi2023_poznan_mat = as.matrix(ndvi2023_poznan, wide = TRUE)
ndvi_CQ = CQ(ndvi2023_tartu_mat, ndvi2023_poznan_mat)
ndvi_CQ$CQReferences
Gao, Peichao, and Zhilin Li. 2019. “Aggregation-Based Method for Computing Absolute Boltzmann Entropy of Landscape Gradient with Full Thermodynamic Consistency.” Landscape Ecology 34 (8): 1837–47. https://doi.org/10/gkb47k.
HG, Drost. 2018. “Philentropy: Information Theory and Distance Quantification with R.” Journal of Open Source Software 3 (26): 765.
Ilich, Alexander R. 2020. GLCMTextures. https://doi.org/10.5281/zenodo.4310186.
Kalinowski, Tomasz, JJ Allaire, and François Chollet. 2024. Keras3: R Interface to ’Keras’. Manual.
Malik, Karim, and Colin Robertson. 2021. “Landscape Similarity Analysis Using Texture Encoded Deep-Learning Features on Unclassified Remote Sensing Imagery.” Remote Sensing 13 (3): 492. https://doi.org/10.3390/rs13030492.
Nowosad, Jakub. 2024. Bespatial: Boltzmann Entropy for Spatial Data. Manual.
Smith, Annie C., Phoebe Zarnetske, Kyla Dahlin, Adam Wilson, and Andrew Latimer. 2023. Geodiv: Methods for Calculating Gradient Surface Metrics. Manual.
Vallejos, Ronny, Felipe Osorio, and Moreno Bevilacqua. 2020. Spatial Relationships Between Two Georeferenced Variables: With Applications in R. Springer Nature.
Footnotes
Reuse
Citation
BibTeX citation:
@online{nowosad2024,
author = {Nowosad, Jakub},
title = {Comparison of Spatial Patterns in Continuous Raster Data for
Arbitrary Regions Using {R}},
date = {2024-10-27},
url = {https://jakubnowosad.com/posts/2024-10-27-spatcomp-bp3/},
langid = {en}
}
For attribution, please cite this work as:
Nowosad, Jakub. 2024. “Comparison of Spatial Patterns in
Continuous Raster Data for Arbitrary Regions Using R.” October
27. https://jakubnowosad.com/posts/2024-10-27-spatcomp-bp3/.